
ICLR 2026 | LightMem:降低大型模型的长期记忆成本
大规模预训练模型虽然表现出色,但在处理“长对话、多轮交互和跨任务”等复杂场景时,依然面临两大挑战:其一为上下文窗口的限制,在对话持续增长的情况下容易出现信息过载;其二是中间环节的信息丢失问题,即便能容纳所有数据也不一定能有效利用。因此,引入“外部记忆系统”成为必要:将对话内容储存于长期记忆,并在需要时进行检索。然而这一方案的实际应用却带来高成本的问题:频繁调用大模型执行总结和提取、实时解决冲突以及
科技新闻0 阅读
共找到 16 篇相关文章
大规模预训练模型虽然表现出色,但在处理“长对话、多轮交互和跨任务”等复杂场景时,依然面临两大挑战:其一为上下文窗口的限制,在对话持续增长的情况下容易出现信息过载;其二是中间环节的信息丢失问题,即便能容纳所有数据也不一定能有效利用。因此,引入“外部记忆系统”成为必要:将对话内容储存于长期记忆,并在需要时进行检索。然而这一方案的实际应用却带来高成本的问题:频繁调用大模型执行总结和提取、实时解决冲突以及

编程智能体的发展正逐步加快。近日,华为云推出了码道(CodeArts)代码智能体公测版,这一产品融合了代码大模型、集成开发环境(IDE)、自主开发模式等功能,并涵盖代码生成、研发知识问答、单元测试用例自动生成等AI编程技术,具备项目级代码生成、续写及关键功能支持。发布会上,华为云码道的负责人谈宗玮表示,该智能体依托于华为二十余年的研发经验以及海量代码积累,内置了需求管理、系统设计、软件开发等多个高
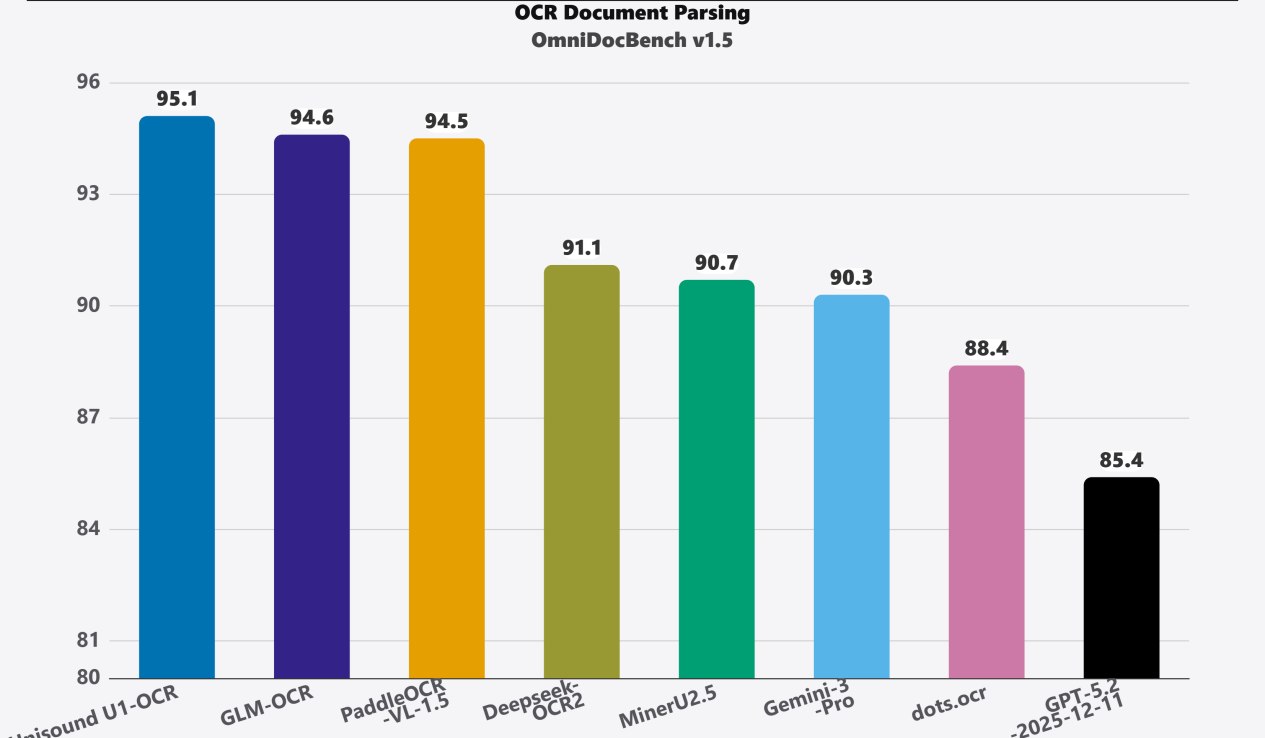
今天,云知声正式发布了Unisound U1-OCR 文档智能基础大模型。 作为首个工业级文档处理平台的基础模型,它凭借“性能领先、值得信赖、易于使用、高效部署和高度适配”五大核心优势,突破了传统文档处理的限制,并确立了行业新标准。 文档智能是指运用人工智能技术自动读取并理解文档影像内容,进行分类及关键信息提取。 传统的OCR解决方案(1.0版)以CRNN为代表,只能识别文字。新一代方案(2.0
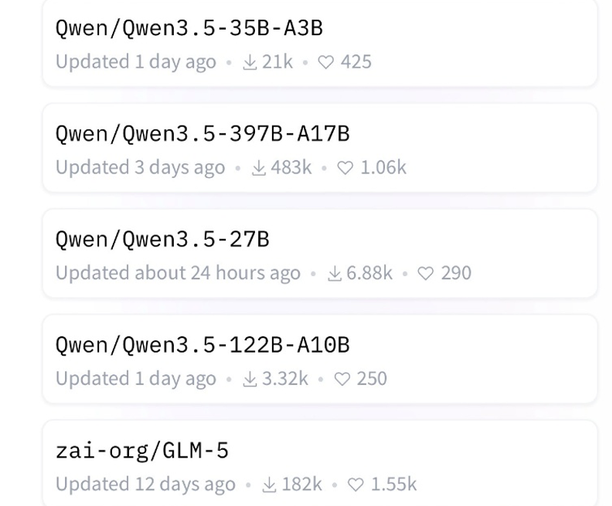
2月26日,全球最大AI开源社区Hugging Face发布了最新的排行榜,阿里千问3.5模型包揽了前四名的位置,成为全球最热门的开源模型之一。据了解,新上榜的三款中型千问3.5模型在多个榜单中的表现均明显优于GPT-5 mini,并且其原生多模态能力和代理功能强大,性能达到了中等尺寸模型的新高度。部分模型甚至可以直接部署在消费级显卡上,在开源不到24小时内便成功登顶。最新一期全球开源模型排行榜显
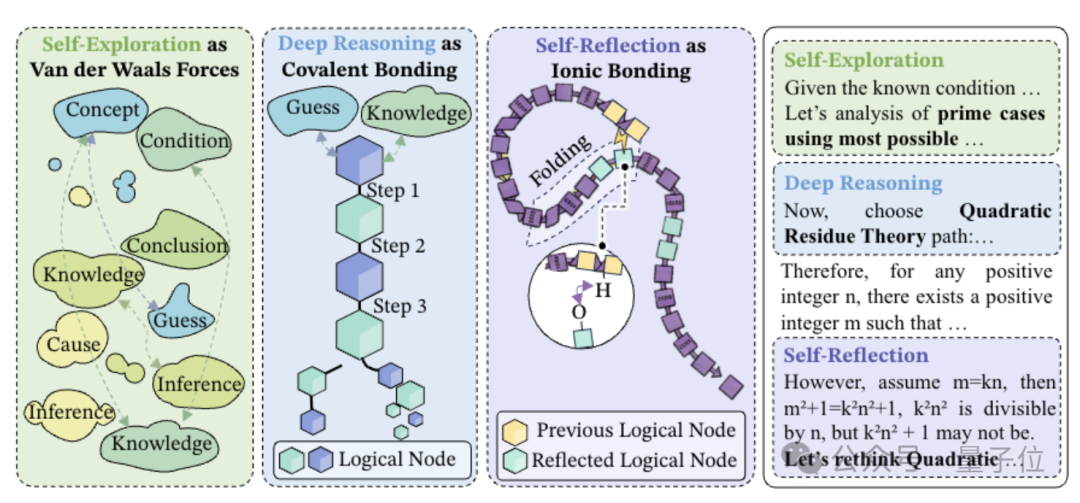
字节Seed开始运用化学原理来研究大型模型。 深度推理像是共价键,自我反思类似氢键,而自我探索则像范德华力? 传统的长思维链推理通常将AI的思考过程视为线性结构。 实际上,在很多情况下,后续的重要结论需要返回去验证早期提出的假设。 CoT忽略了这种非线性的依赖关系。 在论文《思想的分子结构》中,字节Seed首次为大模型定义了长链思维的分子式结构。 这种分子拓扑结构里,三种键是如何相互作用的?

智东西作者程茜编辑云鹏2月25日,据彭博社报道,知情人士透露上海大模型企业阶跃星辰正在考虑在香港交易所进行首次公开募股(IPO),计划筹集约5亿美元(约合人民币34亿元)。据了解,阶跃星辰已与潜在顾问就股权出售事宜进行了沟通,最早可能在今年上市。其发行规模和上市时间等具体细节可能会有所调整。对于IPO的传闻,阶跃星辰尚未作出回应。2月2日,阶跃星辰最新发布的MoE模型Step 3.5 Flash在

近日,国内领先的AI云计算服务提供商阿里云推出了一系列重要更新。一哥就有一哥样。刚刚复工之际,阿里云一口气发布了Qwen3.5、GLM-5、MiniMax M2.5和Kimi K2.5四款顶尖开源模型。这些新上线的模型无疑具有重要意义:Qwen3.5作为阿里自主研发的新一代旗舰级大模型,在算力消耗极低的情况下,其性能已超越当前多个顶级闭源模型,并在Hugging Face榜单上占据榜首位置。Min
千问3.5在Hugging Face社区中位居榜首,前十名开源模型中有八款来自中国 于2月24日,全球最大的AI开放平台Hugging Face发布了最新的开源大模型排行榜,其中阿里巴巴最新发布的原生多模态模型千问3.5荣登榜首。该模型自除夕夜发布以来,迅速引起

轻舟智航重新回归高端市场:L2+车型量产已突破百万大关,城市NOA功能也下放到十万级车型中。 在自动驾驶领域,到2026年,“收敛”一词被广泛认为是行业发展的关键词之一。 技术层面而言,多模态的大模型、数据驱动及强化学习等新兴方法展现出一种阶段性“终局”的特点:

中国团队在太空计算能力方面取得了领先地位:首次实现了通用大型模型的轨道部署,并计划通过发射2800颗卫星为数亿个硅基智能体提供服务。 一凡 发自 凹非寺 量子位 | 公众号 QbitAI 岁末年初,全球AI竞争聚焦到了最新趋势—— 太空算力。 大洋两岸,近期你追

近年来,基于大模型的文本检索技术取得了显著进展,最新的领先技术(SOTA)中,LLM Embedding Model 的参数量通常超过70亿。虽然相关性搜索性能得到了提升,但部署成本也随之大幅增加。众所周知,LLM Embedding Model 使用对称双塔架构,其中查询端和文档端常常共享同一完整的大型语言模型(LLM)。然而,一个长期被忽视的问题是:在

在评估大语言模型(LLM)生成代码的能力时,一个日益凸显的问题浮现出来:当这些模型在 HumanEval 和 MBPP 等经典基准测试中取得近乎饱和的成绩时,我们究竟是在衡量其真实的泛化推理能力,还是仅仅检验它们对训练数据的记忆力?目前的代码基准正面临两大核心挑战:一是数据污染的风险,二是测试严谨性的不足。前者可能使评测退化为「开卷考试」,而后者常常导致一

智东西作者 陈骏达编辑 漠影当大模型在推理、编程等领域不断刷新纪录时,一个新的问题也随之浮现:如何在提升模型能力的同时,控制算力和资源消耗?近期,蚂蚁集团inclusionAI团队发布了一项重要成果——百灵大模型家族的新一代开源万亿参数模型Ling-2.5-1T(即时模型)与Ring-2.5-1T(思考模型)。两款模型并非单纯通过增加参数量取胜,而是依靠共

新智元报道SSI-Bench是首个专注于评估模型在约束流形中空间推理能力的基准,强调真实结构和具体限制条件,通过排序任务来考察模型对三维几何与拓扑关系的理解程度,揭示了当前大模型在处理实际空间问题时严重依赖二维信息的情况,并且其表现远逊于人类。如果将一个在空间理解榜单中得分很高的多模态大型模型直接放置于现实世界环境中,它很可能会在看似简单的任务上遇到困难。

2026年的马年初五(2月21日),当朋友圈被“恭喜发财”刷屏时,一家AI公司也在完成一场“迎财神”。红星资本局2月21日消息,2月20日,港股市场迎来一场由清华校友“点燃”的AI狂欢。在恒生科技指数收跌近3%的情况下,AI大模型龙头智谱(02513.HK)股价逆势收涨,单日暴涨42.72%,报725港元,股价再创新高,总市值达3232亿港元。上市43天,

2026.02.22智谱发布面向开发者的致歉信 资料图本文字数:1274,阅读时长大约2分钟2月21日晚,智谱发布面向开发者的致歉信,承认在GLM Coding Plan上线中存在三大问题:规则透明度不足、GLM-5灰度节奏过慢、老用户升级机制粗糙,并同步公布处理和补偿方案。GLM Coding Plan是智谱专门为AI编程场景推出的付费订阅套餐服务,开发