字节Seed开始运用化学原理来研究大型模型。
深度推理像是共价键,自我反思类似氢键,而自我探索则像范德华力?
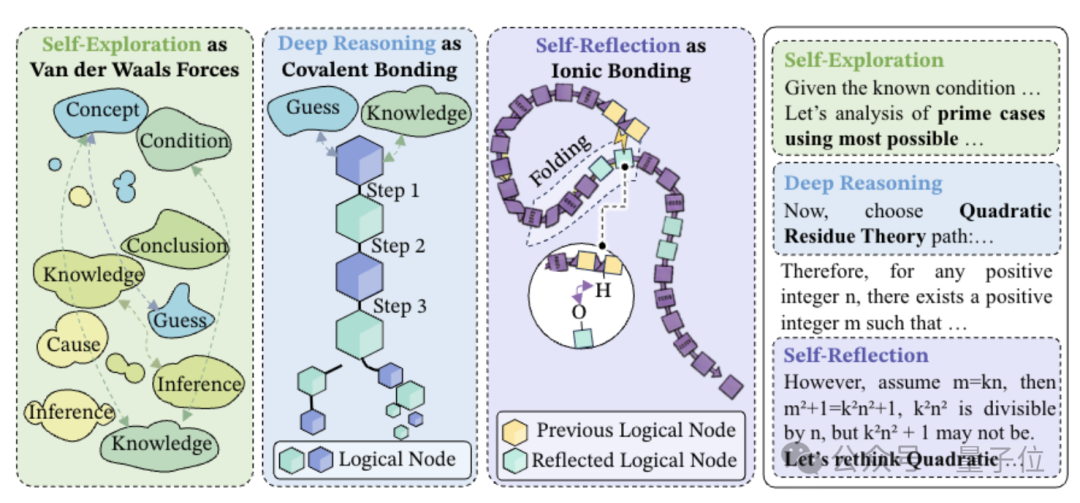
传统的长思维链推理通常将AI的思考过程视为线性结构。
实际上,在很多情况下,后续的重要结论需要返回去验证早期提出的假设。
CoT忽略了这种非线性的依赖关系。
在论文《思想的分子结构》中,字节Seed首次为大模型定义了长链思维的分子式结构。

这种分子拓扑结构里,三种键是如何相互作用的?
研究团队将DeepSeek-R1、gpt-OSS等强推理模型的长链思维拆解,并对每一步之间的“跳跃”进行标记。
完成标签后发现,在所有有效的长链思维中,只有三种基本动作来回组合。
第一种称为深度推理,像共价键一样稳固。
这个可以理解为类似“因为A所以B,因为B所以C”的硬逻辑推进方式。
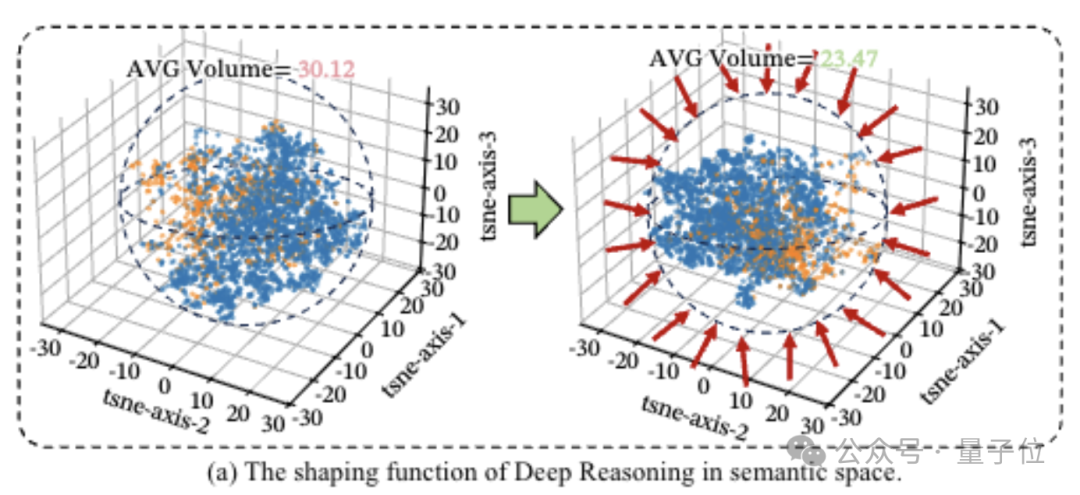
团队在语义空间内进行了一项形象的量化分析,将模型每一步思考视为一个点,并观察这些点最终形成多大的圈。
圈子越小表示模型跑题少、思维聚焦性强。
结果显示,在加入深度推理之后,散点圈缩小了22%。
深度推理确实起到了集中注意力和锁定核心逻辑的关键作用。
第二种称为自我反思,像氢键一样有弹性但稳定。
这类似于“等等,我刚才那步是不是错了”或“让我重新检查一下前面的假设”,可以将后面的思考引回到之前的节点上。
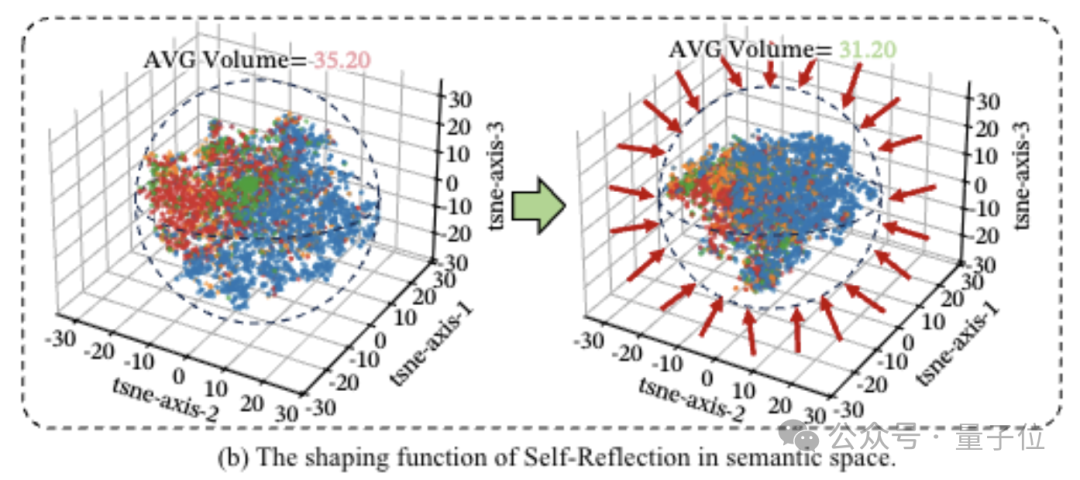
团队分析了模型在进行自我反思时的思维轨迹,并计算其会在语义空间中的哪个位置跳跃返回。
发现81.72%的反思步骤,都准确地回到了之前已经验证过的可靠思路区域。
同样还比较了反思前后的思维范围,反思前为35.2,而反思后直接压缩到31.2。
聚类结果也更明确显示,反思之后同一类正确思路的点会紧密聚集在一起,而那些偏离的想法会被自动推开。
这意味着自我反思能够将合理逻辑揉得更紧实,并且排除不合理的推理路径,使长链思考更加紧凑有序。
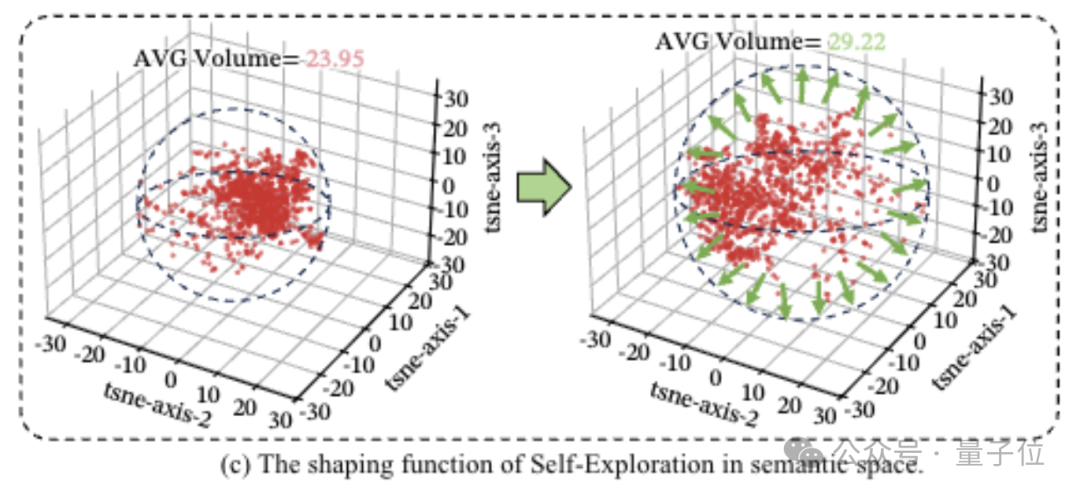
第三种称为自我探索,像范德华力一样微弱但覆盖范围广。
类似于“或许我们可以尝试这个角度”或“是否还有其他可能”,在语义空间内寻找新的解题方向。
量化分析表明,加入探索行为后,模型的思维覆盖范围从23.95扩大至29.22。
尽管思路开放可能会降低稳定性,容易跑偏,但有助于跳出死胡同并找到全新的解题路径。
研究发现所有强推理模型中的三种行为比例和转换规则高度一致,相关性超过0.9,表明有效的长链推理存在通用的稳定拓扑结构。
虽然“共价键”、“氢键”的比喻看起来只是形象化描述,但论文揭示了背后的数学对应关系。
Transformer中的注意力权重计算方式如下:
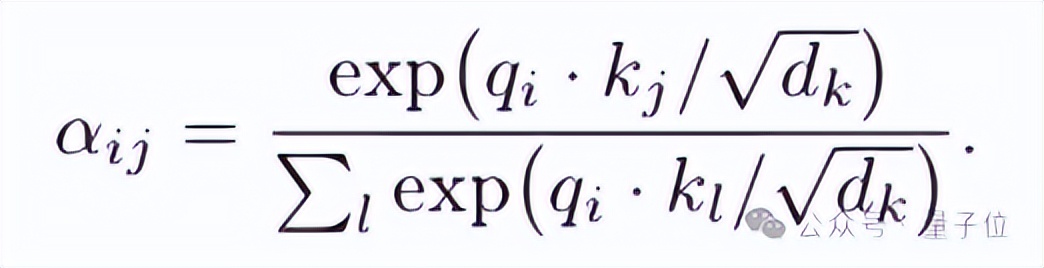
这与统计力学中玻尔兹曼分布相似:
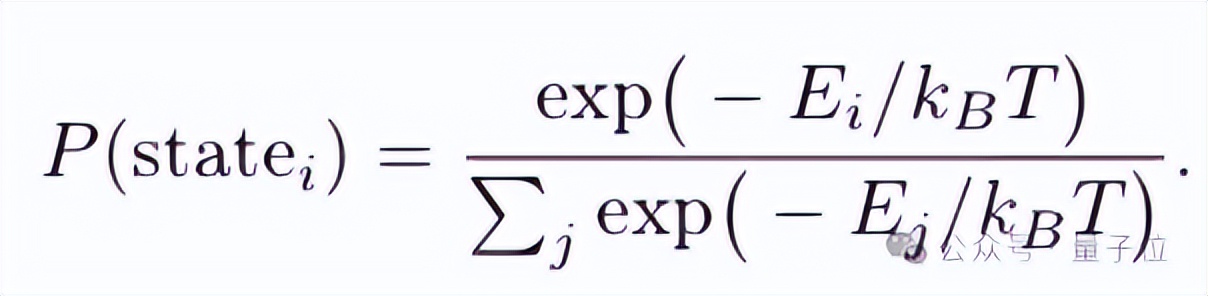
如果把负注意力分数视为能量,那么模型在语义空间里选择路径的概率就取决于“能量”的高低。
论文进一步探讨了三种行为对应的“注意力能量”。
- 深度推理通常发生在相邻步骤之间,能量最低;
- 自我反思会跳回较远的步骤,能量中等;
- 自我探索则跳跃更远,能量最高。
这解释了为什么强推理模型中的三种键比例如此稳定。
因为模型注意力机制本身追求的是最低能量路径,而深度推理、反思和探索正好对应不同距离下的能量层级。
接下来团队提出了语义同分异构体的概念。
这一术语借用化学中的概念,即相同的分子式可以通过不同的原子连接方式形成性质完全不同的物质。
在推理过程中则是指相同的问题和概念点可以通过不同“化学键”组合得到完全不同的推理路径但同样可以得出正确答案。
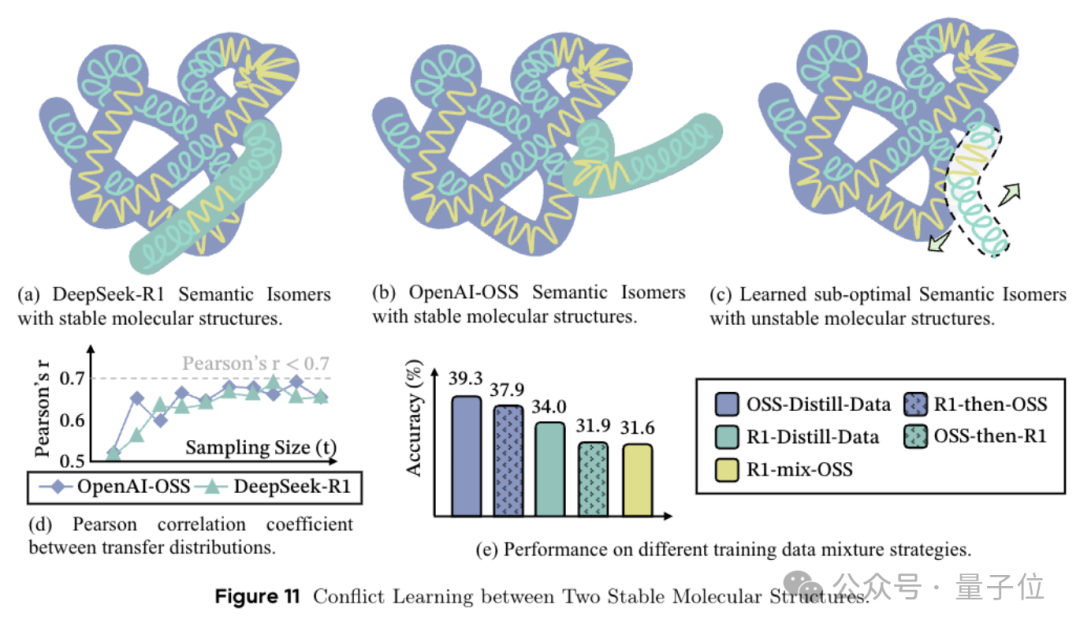
然而,并非所有异构体都适合用于训练模型。
这里引入了熵减这一关键概念。
在热力学中,孤立系统倾向于自发地走向混乱状态(熵增),有效的长链推理过程则是在语义空间内不断减少不确定性——
从诸多可能的方向逐步收敛到唯一正确的答案。这个过程被称为“熵减”。
而“注意力能量”机制正是模型实现这一目标的工具。
模型天生偏好低能量路径。
当深度推理(低能量)被反复选中,反思(中等能量)将前后逻辑折叠起来,探索(高能量)偶尔探路但不主导整个过程,系统的“推理熵”会快速下降,逻辑迅速收敛。
如论文所述,只有那些能推动熵快速降低的“化学键”组合才是模型真正可以学会并持续进化的稳定状态。
在实验中有一个典型现象:从R1和OSS两个不同强推理模型中蒸馏出的推理轨迹,在语义层面上相似度高达95%,但混合训练时模型会崩溃。
这表明,长链推理的关键在于思路结构必须稳定且统一,这样才能被有效学习到。
发现问题就要着手解决。
基于这些发现,团队开发了一种名为MoLE-Syn的方法来从零合成稳定的推理结构。
具体操作就两步。
第一步是从强推理模型(如R1、QwQ、gpt-OSS)的推理链中提取一张行为转移概率图。
图中的每个节点代表一种推理行为,每条边表示从一个行为跳转到另一个行为的概率。

第二步是依据这张图让普通指令模型生成遵循该概率分布的推理链。
使用这种方法合成训练数据后,输入Llama或Qwen等模型的效果接近直接蒸馏R1的水平。
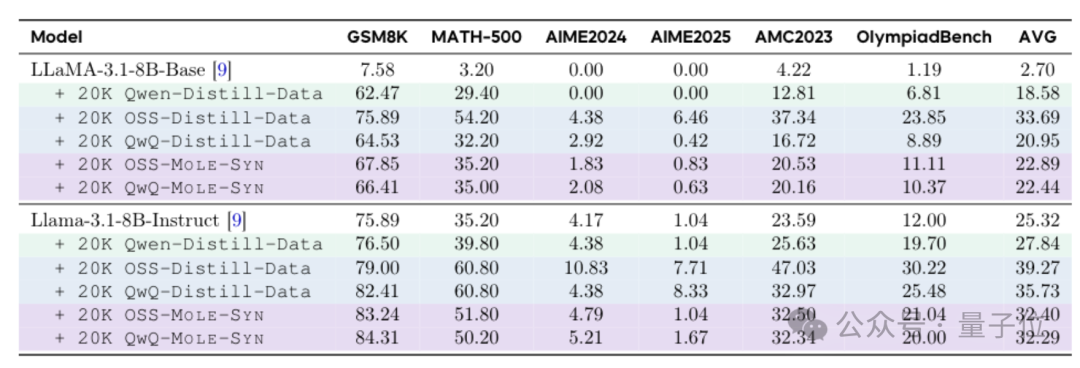
而且这样做还有一个显著的优点就是成本低。只要拥有行为转移图,普通的模型就能自行生产合格的长链推理数据。
采用MoLE-Syn初始化后的模型在强化学习中表现稳定。
相比直接使用蒸馏数据初始化的模型,在RL过程中MoLE-Syn版本的收益持续增长且震荡较小。
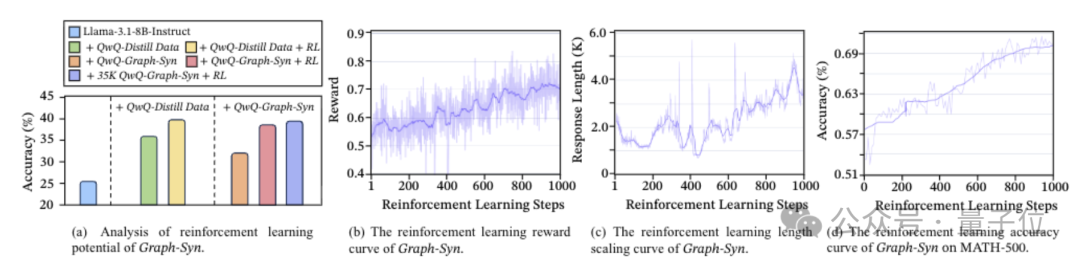
这表明初始植入的思维结构越稳固,后续的强化学习就不会出现逻辑偏移。
此研究由字节Seed算法专家黄文灏负责,他曾任职于微软亚洲研究院研究员职位。
第一作者为哈尔滨工业大学博士生、字节Seed实习研究员陈麒光。
合作单位包括北京大学、2077AI Foundation、南京大学、M-A-P及中南大学等。
这次操作确实让人联想到薛定谔利用物理学公式推导生物学理论的开创性工作。
给大模型推理这一竞争激烈的领域带来了清新且富有创意的新视角。
论文地址:https://arxiv.org/abs/2601.06002
— 完 —