
近年来,基于大模型的文本检索技术取得了显著进展,最新的领先技术(SOTA)中,LLM Embedding Model 的参数量通常超过70亿。虽然相关性搜索性能得到了提升,但部署成本也随之大幅增加。
众所周知,LLM Embedding Model 使用对称双塔架构,其中查询端和文档端常常共享同一完整的大型语言模型(LLM)。然而,一个长期被忽视的问题是:在实际应用中,查询端是否真的需要与文档端同样规模的大模型?我们的最新研究论文《LightRetriever》对此给出了明确、激进但经过大量实验证实可行的答案:不需要。
在 LightRetriever 中,我们设计了一种极端非对称的 LLM Embedding Model——文档侧使用完整的 LLM 进行建模,而查询侧仅使用一层嵌入查找。这种方法极大地降低了查询端的计算负担,同时仍能保证大模型文本检索的效果。与标准设计相比,LightRetriever 将查询端推理速度提升了千倍以上,并使端到端 QPS 提升了10倍,在 BeIR 和 CMTEB Retrieval 等测试集上的中英文检索性能保持在95%左右。
该研究由中科院信工所和澜舟科技共同完成,已被国际顶级会议 ICLR 2026 接收。ICLR 是机器学习与表示学习领域的顶级学术会议之一,其影响力仅次于 NeurIPS 和 ICML。本次 ICLR 2026 收到了约19,000篇有效投稿,接受率为28%。

- 论文标题:《LightRetriever: A LLM-based Text Retrieval Architecture with Extremely Faster Query Inference》
- LightRetriever 提出了一种极端非对称的 LLM Embedding Model 设计思想:将深度建模的主要计算负担完全转移到文档侧,而查询侧仅保留必要的、可缓存的表征能力。此设计为稠密和稀疏检索两种主要范式分别提供了极致非对称的建模方法。
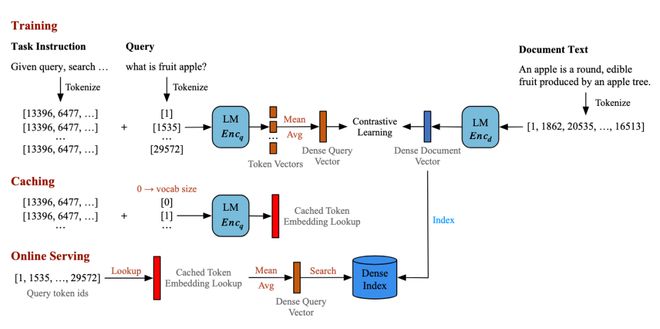
在稠密检索中,LightRetriever 使用了词袋化的方法来显著降低查询推理成本:完整的 LLM 接收“指令+单个 Query Token”作为输入,先生成 Token Embedding,再求平均得到 Query 向量,并通过对比学习获得 Prompted Token Embedding。这些 Token Embedding 在训练完成后可被整体缓存为词表级 Embedding 矩阵,在线推理时仅需一次简单的查表操作即可完成查询向量的计算。
由于在训练阶段仍需要完整 LLM 建模,稠密检索遵循“训练全量 + 推理轻量”的思想。消融实验表明,“训练全量”这一配置不可忽略。
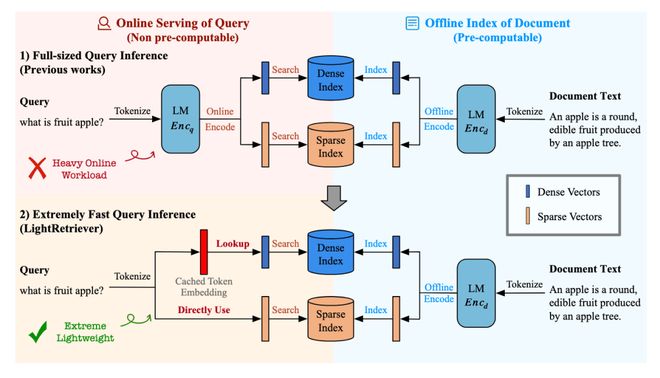
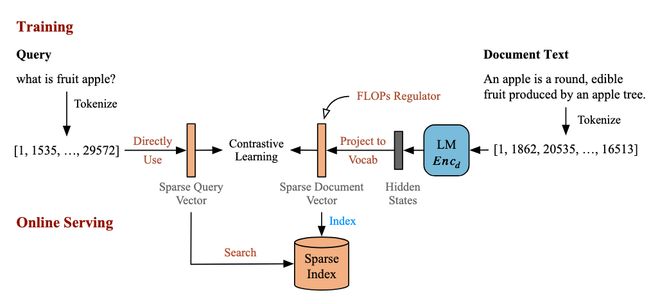
在稀疏检索中,LightRetriever 将查询侧进一步简化为词频映射,完全移除了可学习的模型参数。通过 Doc 侧的 LLM 学习类 SPLADE 方法的 TF-based 稀疏向量,实现了无 LLM 的高效化在线推理。
极端轻量化的设计并没有导致性能显著下降

这表明,在大多数相关性导向的任务中,查询端并不需要完整的深度 Token 交互即可匹配文档侧所学习到的语义结构。
文章还详细比较了 LightRetriever 在不同任务中的细粒度性能表现。例如,在 BeIR 中,LightRetriever 在常规的相关性检索任务中表现出色,接近全对称结构的93%以上;而在更具挑战性的 OOD 任务(如 Domain-specific QA、Entity Retrieval 和 Citation Prediction)中,其性能保持在87%-89%之间。尽管相对性能有所下降,但绝对值仍具有竞争力。
表. BeIR 不同任务中 LightRetriever 的性能表现及变化

通过消融实验验证了“训练全量 + 推理轻量”设计的合理性:如果文档侧或查询侧使用词袋化方法,则会导致性能显著下降。这说明,在大模型文本检索中,移除深度建模并非偶然设计。
消融实验一(A1)表明文档侧始终需要完整建模,而查询端可通过词袋化方法进行近似建模。消融实验二(A2)证明了 LightRetriever 的关键在于将计算负载卸载至不同阶段——在训练时与文档充分交互,在推理时最大化复用可缓存的 Query 词向量。
总结而言,当查询端部署不再是负担,LLM 检索才真正具备扩展性。LightRetriever 表明高质量 LLM Embedding Model 并非必然意味着高昂的在线推理成本。通过明确区分查询与文档在检索流程中的角色,并打破对称建模这一长期默认的设计假设,系统可以在保证效果的前提下显著提升效率。
直觉上,移除 Query 侧的深度上下文建模会显著损害检索效果。然而,大规模实验结果给出了一个出乎意料的结论:
在 BeIR(英文)与 CMTEB-Retrieval(中文)等多任务文本检索基准上,相对完整的对称式 LLM Embedding,LightRetriever 的 nDCG@10 排序指标只下降1–5 pp,平均性能保持率约为95%。更重要的是,该方法的性能水平大幅超过传统稀疏方法(BM25、SPLADE)以及多种轻量化或蒸馏检索模型,并逼近了类似开源训练语料的配置下,LLM2Vec、E5-Mistral 等经典的 LLM Embedding 方法。
这表明:在绝大多数相关性导向的检索任务中,Query 侧并不需要完整的深度 Token 交互,也能够匹配 Doc 侧所学习到的语义结构。
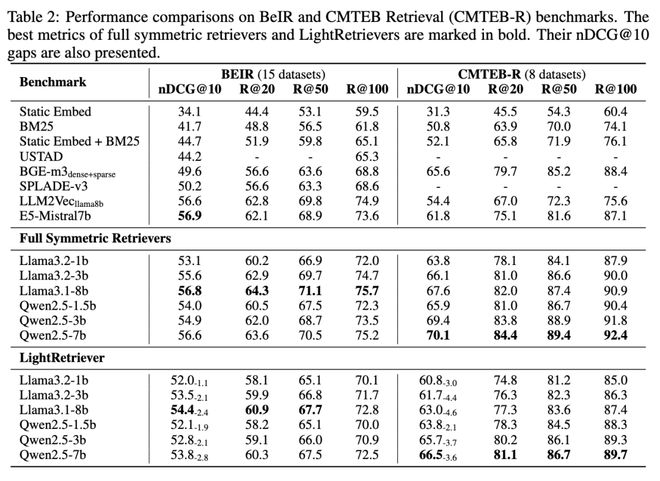
表. BeIR / CMTEB-Retrieval 主实验结果,包含经典 Embedding Model Baseline、对称式 Full LLM Retriever 与 LightRetriever 的检索效果。
文章对比了 LightRetriever 在不同任务中的细粒度性能表现。以 BeIR 为例,LightRetriever 在大多数常规的相关性检索任务中性能表现十分优异,是全对称式结构的 93% 以上;在 Domain-specific QA、Entity Retrieval、Citation Prediction 等更具挑战性的 OOD 任务中,性能维持在全对称式结构的 87%~89%。虽然相对性能略有下降,这些任务性能的绝对数值仍然具备较强的竞争力。
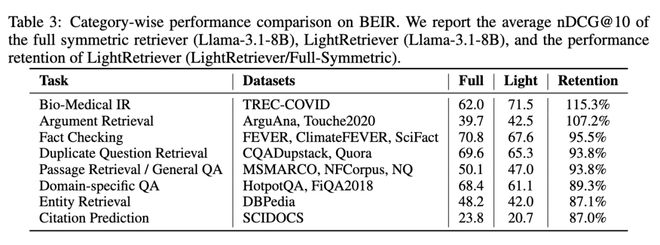
表。在 BeIR 的不同任务中,LightRetriever 的性能表现及相对变化(Retention)。
查询服务速度大幅提升
LightRetriever 的 Query 轻量化设计,为查询推理效率带来了数量级的提升
在 MSMARCO 检索场景下对 64k 查询进行检索,完整的 Llama-8B 查询编码需要超过100 秒;而 LightRetriever 的查询编码时间仅为0.04 秒,对应超过 1000×的编码加速。即便考虑 Faiss 与 Lucene 的检索时间,端到端吞吐仍然获得了10× 以上的 QPS 提升。文章还尝试了一个经典的 Transformers Layer 裁剪 Baseline:在 Query 侧只用 Llama-8b 的第一层 Transformers Layer 用于训练和推理。然而,这个设置的检索性能和 QPS 均不如 LightRetriever,因为训练时 Query 侧没有完整的 LLM 建模。这证明了文章中 “训练全量 + 推理轻量” 的设计的合理性。
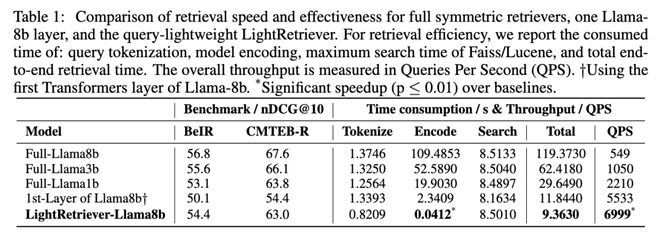
表。查询编码时间 / 端到端 QPS 对比
为什么这种 “训练全量 + 推理轻量” 是必要的,而不是偶然有效?
在 LightRetriever 的稠密检索中,Query 侧在训练时使用全量(Full)建模、推理时转化为 Embedding Layer(Emb)高效化推理。为了验证这种设计的合理性,文章进行了以下两组消融实验:
A1) Doc 侧在推理时也使用 Embedding Layer。
A2) Query 侧在训练时直接用 Embedding Layer。
两者均会引起性能的大幅下降。这说明:在大模型文本检索中,移除深度建模并非偶然设计。
消融实验一(A1)证明了:Doc 侧始终需要完整建模,而 Query 侧可通过词袋化方法做到近似建模。
消融实验二(A1)证明了:LightRetriever 的关键不在于 “减少建模”,而在于将建模负载卸载至不同阶段—— 在训练阶段与 Doc 侧充分建模,在推理阶段最大化复用可缓存的 Query 词向量,即 “训练全量 + 推理轻量”。
从这一角度看,LightRetriever 并不是一次针对模型结构的微调,而是对 LLM 双塔模型计算范式的重新审视。
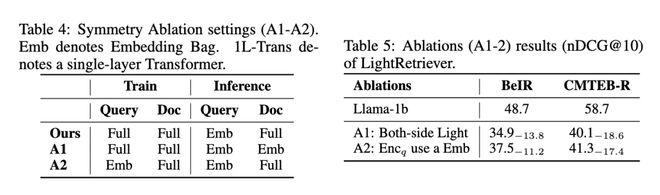
表。对称性消融实验。A1) Doc 侧推理时也进行了词袋轻量化;A2) Query 侧训练时直接使用了 Embedding 词袋。两者效果均显著下降。
结语:当 Query 侧部署不再是负担,LLM 检索才真正具备可扩展性
LightRetriever 表明,高质量的 LLM Embedding Model 并不必然意味着高昂的在线推理成本。通过明确区分 Query 与 Doc 在检索流程中的角色,并有意识地打破对称建模这一长期默认的设计假设,检索系统可以在维持效果的前提下,获得数量级的效率提升。
对于面向真实应用场景的检索系统、RAG 框架与在线搜索服务而言,这种查询轻量化的建模思路,或许比单纯追求更大的模型规模更具应用价值。
作者简介
文章第一作者为中国科学院信息工程研究所博士研究生马广远,研究方向为大模型信息检索,导师是虎嵩林研究员。本文在微软亚研院前副院长、现澜舟科技 CEO 周明博士和虎嵩林研究员的共同指导下完成。