
在评估大语言模型(LLM)生成代码的能力时,一个日益凸显的问题浮现出来:当这些模型在 HumanEval 和 MBPP 等经典基准测试中取得近乎饱和的成绩时,我们究竟是在衡量其真实的泛化推理能力,还是仅仅检验它们对训练数据的记忆力?
目前的代码基准正面临两大核心挑战:一是数据污染的风险,二是测试严谨性的不足。前者可能使评测退化为「开卷考试」,而后者常常导致一种错误的安全感——模型生成的代码或许能在少量示例中通过测试,但在复杂的实际场景中却不堪一击。
为了打破这种高分幻觉,北京航空航天大学的研究团队提出了一种全新的基准构建方法 —— 双重扩展(Dual Scaling),并基于此创建了端到端的自动化框架 Code2Bench。该研究旨在为大模型代码生成评估建立一个更动态、更具挑战性且诊断能力更强的新标准。
目前,这项研究成果已被 ICLR 2026 接收发表。

- 论文标题:Code2Bench: Scaling Source and Rigor for Dynamic Benchmark Construction
- 榜单链接:https://code2bench.github.io/
- 我们需要什么样的代码基准测试方法?
理想的评测标准不应仅仅是静态题库的简单组合,而应该是一个不断进化的对抗环境。它必须同时满足两个条件:题目对模型而言是全新的,以防止记忆作弊;测试则须足够严格,能够揭示逻辑上的脆弱点。
然而,当前大多数评测体系仍受限于「一次性构建、长期复用」的旧模式。它们要么依赖人工编写(易受污染),要么从竞赛平台获取数据(脱离实际开发环境);测试案例通常稀疏且浅层,只能验证功能可用性,却无法评估生产可靠性。
表一:现有主流代码生成基准多维度对比
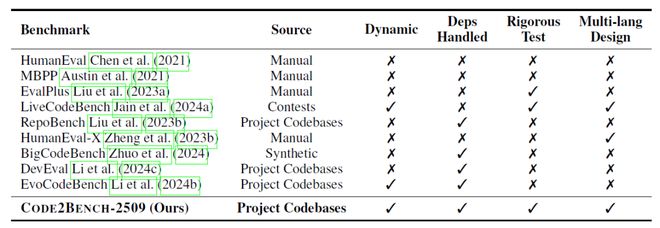
表一直观地揭示了当前评测界的「能力缺口」:大多数基准要么依赖人工编写(易被后续训练集污染),要么从竞赛平台抓取(往往脱离工程实际逻辑)。更致命的是,它们的测试案例普遍稀疏且浅层,只能验证功能可用性,却无法区分生产可靠性。
为了填补这一空白,未来的基准构建方法必须具备以下四大特质:
动态性:问题来源需是持续更新的,以从根本上对抗数据污染。
- 真实性:题目应源自真实的复杂项目代码库,而非人工编写的「玩具问题」。
- 严谨性:测试必须深入且全面,能够挖掘出最细微的逻辑缺陷。
- 全面性:处理复杂的外部库依赖,并具备向多语言扩展的能力。
- 正是在对这四大目标的追求下,Code2Bench 的核心构建哲学应运而生。
「双重扩展」:重构代码基准的创建逻辑
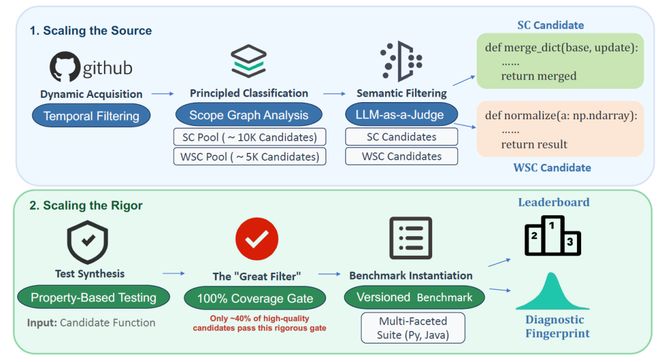
Code2Bench 不仅发布了一个新数据集,还提出了一套端到端、全自动且可持续演进的基准测试框架。通过「双重扩展」方法,评估大模型生成代码的能力从简单的静态谜题复现转变为应对未知工程问题的稳健求解。
未来,研究团队计划进一步扩大 Code2Bench 的应用范围,将代码安全性、执行效率以及仓库级别的生成能力纳入评估范畴。随着评测基准向高压「练兵场」转变,我们期待这一框架能驱动 LLM 跨越「正确幻觉」的鸿沟,最终成为具备工程鲁棒性的智能开发者。
目前,Code2Bench 的代码、数据集以及详细的测试结果已全部开源。研究团队邀请社区共同参与和探索。
与当前最严格的静态基准 EvalPlus(HumanEval 的增强版)相比,Code2Bench-2509 显示出系统性的难度提升。如图所示,所有模型在新基准上的性能均显著低于其在 HumanEval 上的表现——例如,Claude-4-Sonnet 在 HumanEval 上达到 97%,但在 Code2Bench-2509 上骤降至 40.1%。
这一断崖式的下滑揭示了两个关键事实:
- 传统高分包含显著的记忆成分——EvalPlus 虽然加强了测试,但题源仍为多年前人工编写,极易被模型「背过」;
- Code2Bench 则源自真实工程代码——题目动态采自 2025 年后 GitHub 的活跃项目,天然具备复杂控制流和语义深度,无法靠记忆或模式匹配通过。
- 换言之,EvalPlus 是对旧题目的「加固」,而 Code2Bench 则是面向未来的「新战场」。前者测的是「是否见过」,后者问的是「能否创造」。
- 总结与展望:迈向真实工程世界的编程测试
Code2Bench 的本质,不是又一个 benchmark,而是一套可持续演进的评测基础设施。通过「双重扩展」哲学,它将代码 LLM 评估从简单的静态谜题复现,推向未知工程问题的稳健求解。
未来,研究团队计划进一步扩大 Code2Bench 的应用范围,将代码安全性、执行效率以及仓库级别的生成能力纳入评估范畴。随着评测基准从单纯的「考场」进化为高压的「练兵场」,我们期待这一框架能驱动 LLM 跨越「正确幻觉」的鸿沟,最终成长为真正具备工程鲁棒性的智能开发者。
目前,Code2Bench 的框架代码、数据集以及详尽的评测结果已全部开源。研究团队诚邀社区共同参与和探索。
- 基于属性的测试(Property-Based Testing, PBT):框架为每个候选函数自动生成包含数百乃至上千个输入的测试套件,这些输入覆盖了典型值、边界值和复杂的嵌套结构。
- 「Great Filter」——100% 分支覆盖率:这是 Code2Bench 最具标志性的设计。一个函数及其对应的 PBT 测试套件,只有在执行时能够覆盖到函数内每一个逻辑分支(如 if/else 的所有情况),才会被最终采纳。这一看似简单的要求,却是一个极其严苛的质量门,它确保了基准中的每一个问题都是一个逻辑完备且可被深度验证的挑战。
Code2Bench-2509 基准
为了验证「双扩展」哲学的有效性,研究团队基于该框架自动构建了Code2Bench-2509基准套件。这是一份动态摄取自 2025 年 5 月至 9 月 GitHub 最新提交的「实战考卷」,包含 Python 与 Java 的原生实例。
表二的量化指标直观地揭示了 Code2Bench-2509 在工程维度上对传统基准的 「代差」优势:
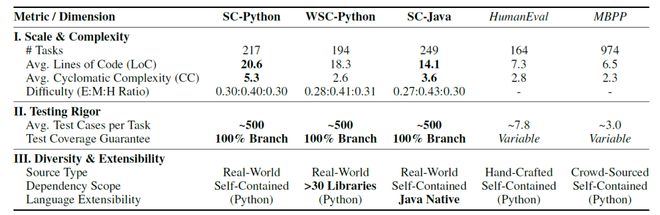
表二:Code2Bench-2509 核心指标
- 复杂度跃升:在纯逻辑(SC-Python)任务中,平均圈复杂度(Cyclomatic Complexity)达到 5.3,远高于 HumanEval 的 2.8。
- 严谨性碾压:不同于 HumanEval 平均每题仅约 7.8 个测试用例,Code2Bench 为每道题生成了约 500 个测试用例。
- 生态多样性:在 WSC 任务中,基准涵盖了超过 30 个主流第三方库(如 NumPy、Pandas、Scipy 等),真实模拟了现代软件开发对 API 应用能力的依赖。
图二的多维评估景观图(Figure 2)则清晰地展示了这一跨越:
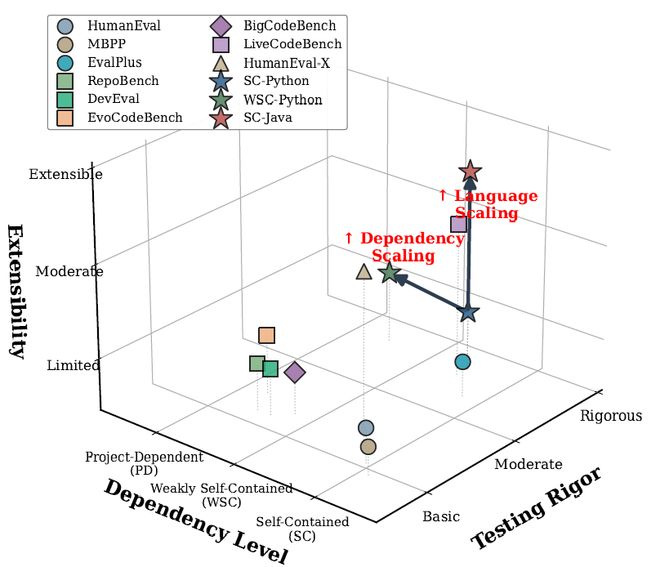
图二:Code2Bench-2509 与主流基准在测试严谨性、依赖深度与可扩展性上的多维对比
相比于 HumanEval 和 BigCodeBench 等主流基准,Code2Bench 在测试严谨性(Testing Rigor)、依赖深度(Dependency Level)以及框架可扩展性(Extensibility)三个维度上均实现了显著的位移。
它不再仅仅停留于考察模型「能否写出正确的代码」,而是通过「语言扩展」和 「依赖扩展」,将评估推向了更广阔的软件工程生态。这种多维度的跨越,为后续揭示模型更深层的能力缺陷奠定了基础。
诊断指纹:揭示能力鸿沟与「性能脚手架」效应
传统的 Pass@1 分数往往是一个「黑盒」:它记录了结果,却掩盖了模型思维的过程。正是得益于 Code2Bench 对测试强度的量级扩展(从个位数跃升至~500 个用例),我们才获得了足以勾勒「错误光谱」的高分辨率视角。
这种「诊断指纹(Diagnostic Fingerprint)」将评估从单一维度的「得分」统计,进化为对模型思维失效模式的深度透视。
从表 3 的 Pass@1 数据中,我们可以观察到不同模型在不同赛道上的 “偏科” 现象:
- 在纯算法任务(SC-Python)上,Claude-4-Sonnet 以40.1%的胜率领跑,凸显了其在无依赖逻辑推理上的深厚底蕴;
- 在API 应用任务(WSC-Python)上,Mistral-small-3.1 表现亮眼(38.7%),与 Claude 持平,显示出其对库调用极高的熟练度;
- 在Java 算法任务(SC-Java)上,DeepSeek-V3 则以 47.8% 的惊人成绩冠绝全场。
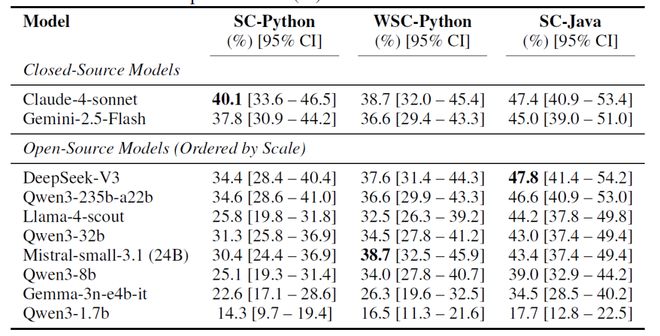
表三:Pass@1 performance (%) on the Code2Bench-2509 suite.
然而,真正的洞察隐藏在图三中 —— 指纹图谱中失败分布的偏移,揭示了两个被单一分数掩盖的关键事实:
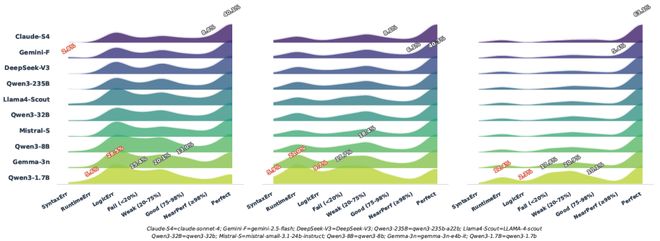
图三:模型诊断指纹对比:SC-Python、WSC-Python 与 SC-Java 的结果分布
1. 能力鸿沟:擅长「调 API」,却在「写算法」上挣扎。
指纹图揭示了模型在面对不同任务时截然不同的思维状态:在纯算法(SC-Python)任务中,失败峰值集中于逻辑错误 (LogicErr);而一旦涉及调用外部库(WSC-Python),峰值则迅速转向了运行时错误 (RuntimeErr)。这清晰地表明,模型目前的瓶颈已从 “记不住 API 参数” 转向了更深层的 “无法自主构建复杂逻辑”。
2.「性能脚手架」效应:语言范式如何塑造模型表现。
更具启发性的是 Python 与 Java 的对比。在SC-Java任务中,Python 中常见的逻辑错误被大幅抑制,完美通过率(Perfect)显著飙升。这并非因为任务变简单了,而是 Java 的静态类型系统扮演了「性能脚手架」的角色 —— 它在代码执行前就强行拦截了大量低级错误。
换言之,指纹图的分布偏移本身,就是语言范式塑造模型能力的直接可视化证据。它揭示了一个关键事实:一个模型的编程能力并非抽象存在;其表现深度耦合于目标语言的生态系统 —— 静态类型不是「限制」,而是一种前置的、高性价比的鲁棒性保障。
「近乎完美」的失败:揭示「正确幻觉」的普遍性
在 Code2Bench 的严苛测试下,平均有6.94%的 SC-Python 任务提交会陷入 「近乎完美」的失败 —— 它们能通过 98% 以上的测试用例,却在最后几个微妙的边缘场景中出错。这些在传统基准中极有可能被计为「成功」的案例,恰恰暴露了模型在逻辑鲁棒性上的「最后一公里」缺陷。
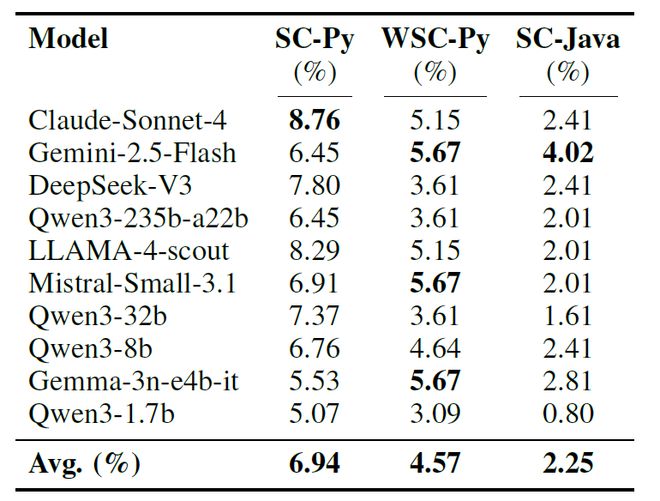
表四:「近乎完美」失败(Pass@≥98% & Pass@<100%)的发生比例
与现有基准的对比:动态性 vs 静态增强
与当前最严谨的静态基准 EvalPlus(HumanEval 的测试增强版)相比,Code2Bench-2509 展现出系统性难度跃升。如图 4 所示,所有模型在新基准上的性能均远低于其在 HumanEval 上的表现 —— 例如,Claude-4-Sonnet 在 HumanEval 上达 97%,但在 Code2Bench-2509 上骤降至 40.1%。
这一断崖式下滑揭示了两个关键事实:
- 传统高分包含显著记忆成分 ——EvalPlus 虽强化了测试,但题源仍为多年前人工编写,极易被模型「背过」;
- Code2Bench 源于真实工程代码 —— 题目动态采自 2025 年后 GitHub 活跃项目,天然具备复杂控制流与语义深度,无法靠记忆或模式匹配通过。
换言之,EvalPlus 是对旧题目的「加固」,而 Code2Bench 是面向未来的「新战场」。前者测的是「是否见过」,后者问的是「能否创造」。
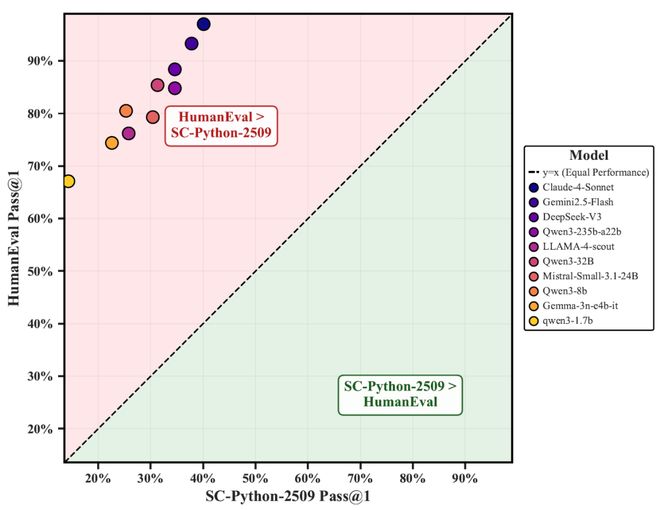
图四:模型在 EvalPlus 和 Code2Bench-2509 上的表现对比
总结与展望:迈向真实工程世界的编程评测
Code2Bench 的本质,不是又一个 benchmark,而是一套可持续演进的评测基础设施。它通过「双重扩展」哲学,将代码 LLM 评估从「静态谜题的复现」,推向 「未知工程问题的稳健求解」。
未来,研究团队计划进一步扩展 Code2Bench 的边界,将代码安全性、执行效率以及仓库级别的生成能力纳入评估范畴。随着评测基准从单纯的「考场」进化为高压的「练兵场」,我们期待这一框架能驱动 LLM 跨越「正确幻觉」的鸿沟,最终成长为真正具备工程鲁棒性的智能开发者。
目前,Code2Bench 的框架代码、数据集以及详尽的评测结果已全部开源,研究团队诚邀社区共同参与和探索。