 智东西作者 陈骏达编辑 漠影
智东西作者 陈骏达编辑 漠影
当大模型在推理、编程等领域不断刷新纪录时,一个新的问题也随之浮现:如何在提升模型能力的同时,控制算力和资源消耗?
近期,蚂蚁集团inclusionAI团队发布了一项重要成果——百灵大模型家族的新一代开源万亿参数模型Ling-2.5-1T(即时模型)与Ring-2.5-1T(思考模型)。
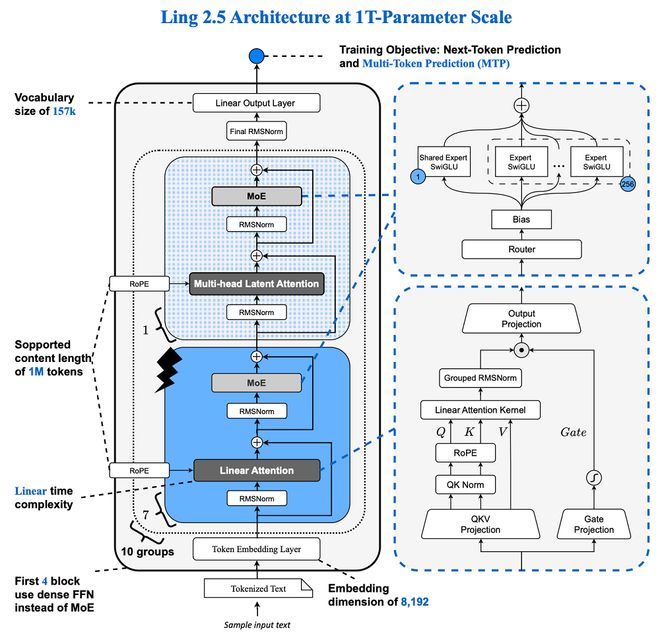
两款模型并非单纯通过增加参数量取胜,而是依靠共同的技术基础——混合线性注意力架构“Ling 2.5”,这一创新是此次发布的核心亮点。在当前主流大模型普遍采用改进型传统注意力机制的背景下,Ling-2.5-1T成为业内罕见的超大型混合线性注意力架构模型,而Ring-2.5-1T则是全球首个基于混合线性注意力架构的万亿参数思考模型。
混合线性注意力架构“Ling 2.5”使得模型在长文本生成与复杂推理任务中,将访存规模降至传统结构的十分之一,并且生成吞吐量提升了三倍。这表明该架构不仅增强了模型的理解和生成能力,还大幅降低了资源消耗。
此外,效率提升并未牺牲性能表现。多项基准测试显示,在涉及推理、智能体操作、指令遵循及长上下文处理等场景中,Ling-2.5-1T的性能超越了DeepSeek-V3.2-nothink、Kimi-K2.5-Instant和GPT-5.2-chat等同类型即时模型。
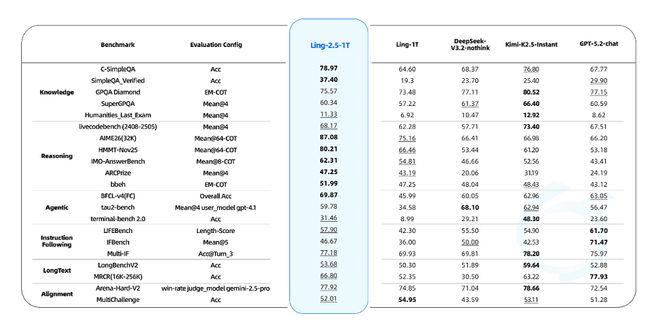
Ring-2.5-1T则在国际数学奥林匹克竞赛(IMO 2025)和中国数学奥林匹克(CMO 2025)中达到了金牌标准,自测分数分别为IMO 35分、CMO 105分。开启重度思考模式后,在IMOAnswerBench、HMMT-25等数学推理基准及LiveCodeBench-v6代码生成测试中,其性能超越所有对比模型。
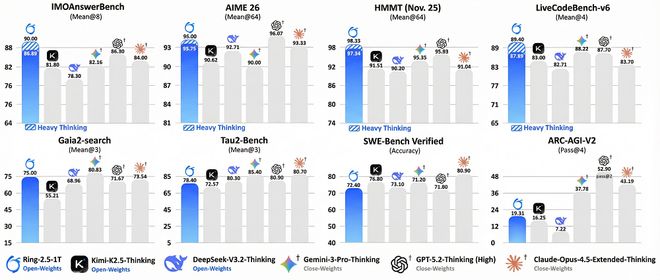
那么,蚂蚁集团百灵团队的混合线性架构技术路线是如何实现的?又如何在不牺牲性能的前提下实现了如此显著的效率提升?
一、万亿参数时代,传统架构还能走多远?
在大模型不断演进的过程中,注意力机制始终占据核心地位,影响着其处理长文本、捕捉复杂语义及生成高质量内容的能力。Softmax作为主流注意力计算方法的基础,几乎被所有Transformer模型采用。
这种机制通过遍历整个上下文来获取精确的词间关联,赋予模型强大的表达能力和精细对齐能力。但随着文本长度增加,其计算量呈平方级增长,导致算力和显存消耗迅速上升。
当应用场景向超长上下文延展时,“精细化”的成本受到重新评估。线性注意力(Linear Attention)因而进入主流视野。
线性注意力通过数学手段降低计算复杂度,不再为每个token反复回顾全部序列,而是依赖状态记忆传递关键信息——更像是接力赛,每一步都承接前一步的结果,无需重复过往路径。这显著提升了效率:更低的FLOPs、更小的显存占用以及更快的生成速度。
然而,线性机制并非万能,在需要精确定位关键信息、进行细粒度语义对齐或复杂长程依赖建模的任务中表现欠佳。于是,一种兼顾性能和效率的技术路径逐渐形成——混合线性注意力架构(Hybrid Linear Attention)。
这种思路直观地将同一模型中的任务进行分层分工:部分层次保留传统机制处理复杂语义与全局依赖,其余则采用线性机制降低计算负担。从而在表达能力和计算效率之间实现动态平衡。
然而,清晰的理念并不意味着实施容易。真正推动混合架构应用于超大规模参数训练仍面临多项挑战。
首先是稳定性问题,在两种机制在同一网络中协同工作时,特别是在大规模预训练环境下,易引发数值波动影响收敛和梯度稳定。
其次是比例调整难题,如何在不同层之间分配传统注意力与线性机制的比例并无通用方案。这需要大量实验验证以找到最优配置。
三、从实验室到真实场景:架构优化带来了什么?
在蚂蚁集团发布的基准测试中,可以直观感受到混合线性注意力带来的性能提升。
AIME 2026评测显示,在平均输出长度为5890个token的情况下,新一代Ling-2.5-1T模型的表现在前一代基础上显著提高,并接近前沿思考模型水平。通常后者需要生成15000到23000个token才能完成同样任务。
在衡量长文本处理能力的RULER与MRCR基准测试中,Ling-2.5-1T的表现优于采用MLA/DSA架构的主流大型即时模型如Kimi K2.5和DeepSeek V3.2。
Ring-2.5-1T则在数学、代码及逻辑等高难度推理任务以及智能体搜索、软件工程和工具调用等长程任务上达到开源领先水平。这些性能提升与混合线性注意力架构在处理长依赖关系和压缩状态方面的优势密切相关。
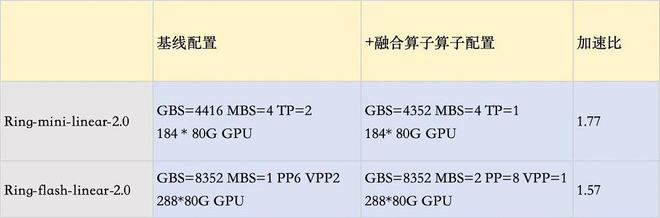
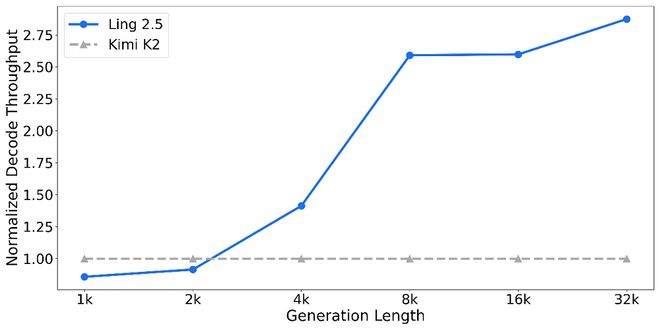
这种架构上的改进也直接转化为实际应用中的效益。即便激活参数量增加至63B,基于混合线性注意力的Ling-2.5模型仍能在单机8卡H200配置下优于前代1T规模模型和同等参数量的Kimi K2。
随着生成文本长度的增加,这种吞吐量优势更加明显,充分展示了混合线性注意力在长程推理场景中的效率优势。
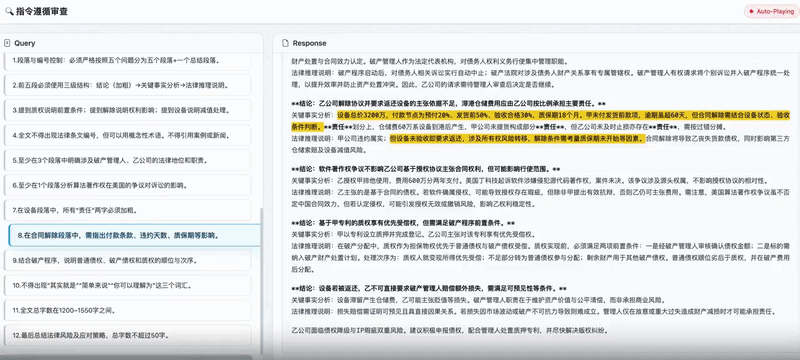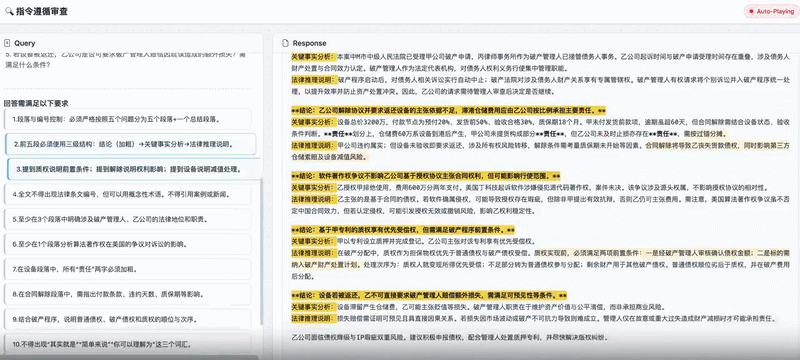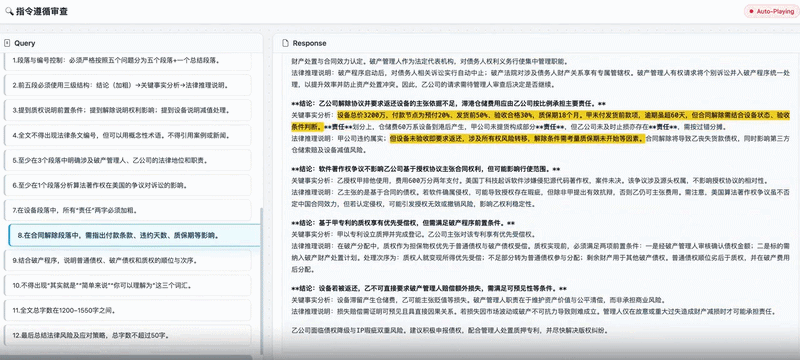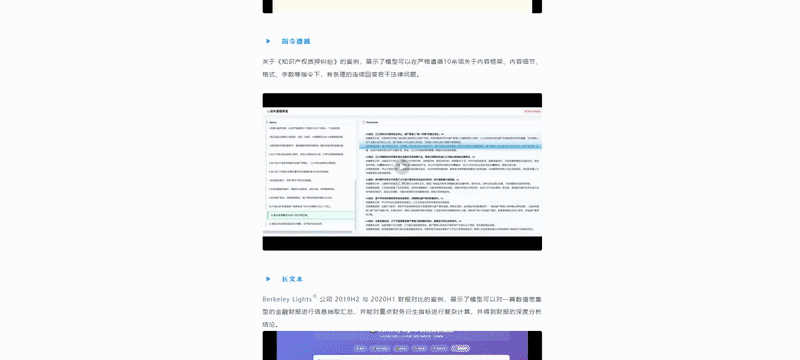
在实际应用案例中,Ling-2.5-1T模型的能力也得到了体现。例如,在处理《知识产权质押纠纷》等复杂法律指令遵循任务时,该模型能够严格遵守超过十项涵盖内容框架、细节、格式和字数等多个维度的指令约束,并生成条理清晰且逻辑连贯的回答。
这归功于优化后的长上下文能力,确保了模型在跨越多个细化指令的过程中保持一致性,避免信息断裂。
另一个例子是在财报解读中,该模型能够抽取汇总数十页的财务报表,并计算重点财务衍生指标以生成深度分析结论。由于巨大的长上下文窗口和高效的token利用率,这类复杂任务无需拆分即可一次完成流畅解析。
这些技术特性在实际应用中的商业价值明显:长期以来,大模型规模化部署受制于高昂的推理成本。此次架构层面优化直接降低了单位请求的算力开销,在相同硬件条件下支持更高并发量,从而降低AI功能集成门槛。
百万token级别的长上下文支持扩展了模型在复杂文档处理场景中的应用范围,如长篇法律文书语义解析和科研文献批量梳理。同时,该模型在多步推理与跨段落信息整合方面的表现,为构建企业级智能体及知识处理自动化系统提供了更稳定的技术基础。
结语:跳出“参数竞赛”,回归架构进化的本质
2月份,蚂蚁百灵大模型家族迎来了一系列重要开源发布——原生全模态模型Ming-flash-2.0、扩散语言模型LLaDA2.1、思考模型Ring-2.5-1T及旗舰基座即时模型Ling-2.5-1T。这一系列模型在多个关键基准上具有竞争力,使蚂蚁稳居国内大模型行业第一梯队。
百灵家族的整体布局显示了其演进逻辑:不单纯追求参数规模增长,而是在多模态感知、语言生成机制、深度推理能力和即时响应效率等核心维度全面布局,构建互为补充和协同进化的模型矩阵。
从行业角度来看,Ling 2.5架构的成功表明架构创新是大模型演进的关键变量。更高的推理效率、更长的上下文处理能力以及更低的部署成本——这些由架构革新带来的系统性优势正重新定义大模型的能力边界。
当技术路线日益多元化和开源生态持续繁荣时,开发者便有了更为灵活的工具组合来应对各种场景挑战。
在蚂蚁对外发布的基准测试中,我们能直观感受到混合线性注意力带来的性能提升。
以AIME 2026评测为例,当平均输出长度约为5890个token时,新一代Ling-2.5-1T模型的表现显著超越前代Ling-1T,并已逼近前沿思考模型的水平。值得注意的是,后者通常需要生成15000到23000个token才能完成同样复杂的任务。
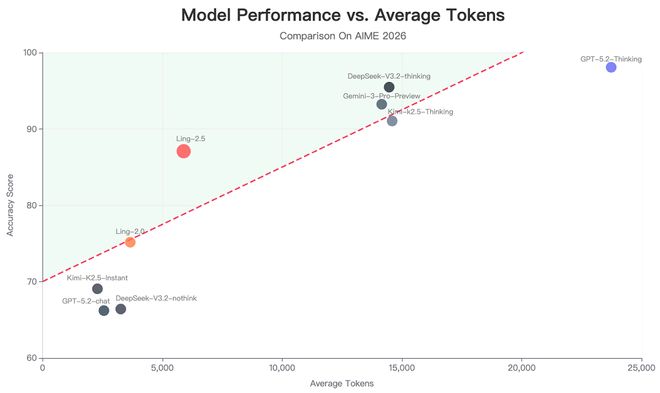
在衡量长文本处理能力的RULER与MRCR基准测试(覆盖16K至256K token范围)中,Ling-2.5-1T取得了优于采用MLA/DSA架构的主流大型即时模型(如Kimi K2.5、DeepSeek V3.2)的分数。
Ring-2.5-1T则在数学、代码、逻辑等高难推理任务和智能体搜索、软件工程、工具调用等长程任务执行上均达到了开源领先水平。这些任务的性能提升,与混合线性注意力架构在处理长程依赖和状态压缩方面的优势密切相关。线性机制实现了高效的上下文信息传递,有效支撑了复杂推理任务对长序列建模的需求。
这种架构上的优势也直接转化为工程实践上的红利。即便在激活参数量增加至63B的情况下,基于混合线性注意力的Ling-2.5在单机8卡H200的配置下,其长文本生成的解码吞吐量(decode throughput)仍显著优于前代1T规模模型以及同等参数量的Kimi K2。
并且,随着生成文本长度的增加,这种吞吐量优势变得越发明显,充分展现了混合线性注意力在长程推理场景下的效率优越性。
模型能力的提升在实际应用案例中同样得到了体现。在下方这个关于《知识产权质押纠纷》的复杂法律指令遵循任务中,Ling-2.5-1T能够严格遵循超过10项涵盖内容框架、细节、格式和字数等多维度的指令约束,生成条理清晰、逻辑连贯的答复。
这得益于优化后的长上下文能力,确保了模型能在跨越多个细分指令的过程中始终保持一致性,避免信息断裂。
而在这个财报解读案例中,模型可以对数十页的财报进行信息的抽取汇总,并对重点财务衍生指标进行计算,得到财报的深度分析结论。
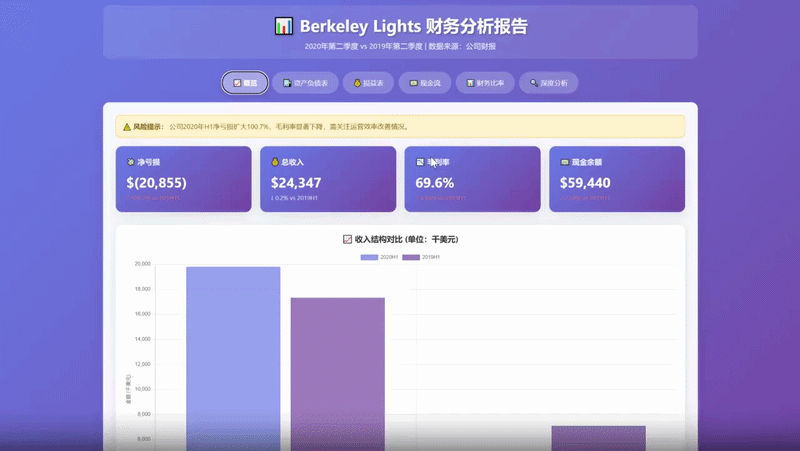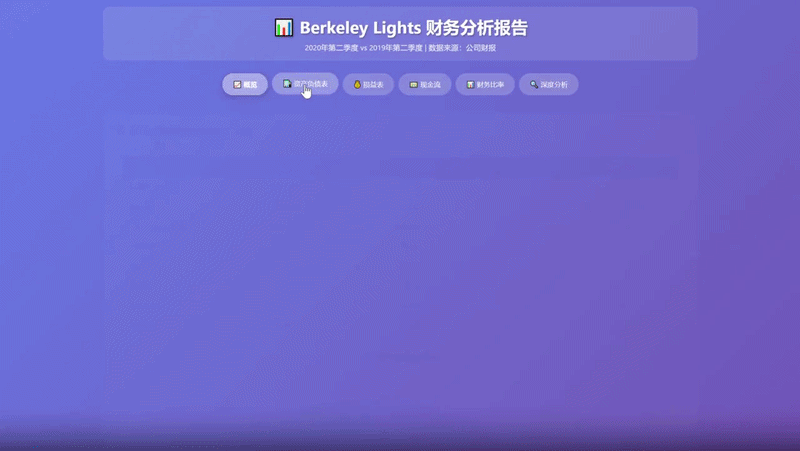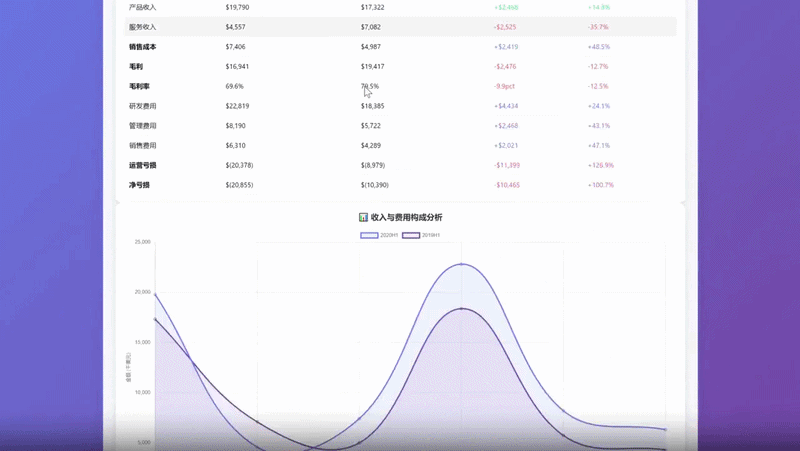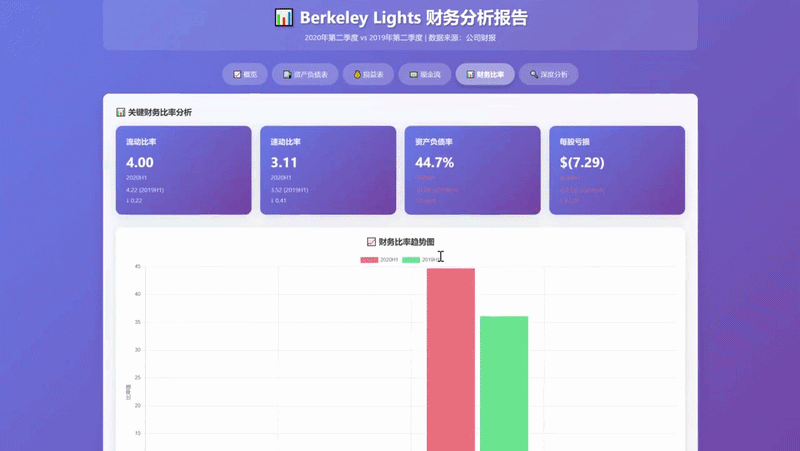
庞大的长上下文窗口与高效的token利用率,使得这类复杂任务无需分解,即可一次性流畅完成。
这些技术特性在实际应用中具有明确的商业价值。长期以来,大模型在规模化部署中主要受限于推理成本,而此次架构层面的优化直接降低了单位请求的算力开销,使企业能够在同等硬件条件下支持更高并发,进而降低AI功能集成的门槛。
百万token级别的长上下文支持,拓展了模型在复杂文档处理场景中的可用性,例如长篇幅法律文书的语义解析、科研文献的批量梳理等。同时,模型在多步推理与跨段落信息整合方面的表现,也为构建企业级智能体及知识处理自动化系统提供了更稳定的技术基础。
结语:跳出“参数竞赛”,回归架构进化的本质
就在2月,蚂蚁百灵大模型家族迎来了一系列重要开源与发布:原生全模态模型Ming-flash-2.0、扩散语言模型LLaDA2.1、思考模型Ring-2.5-1T,以及旗舰基座即时模型Ling-2.5-1T。这一系列模型在多个关键基准上具备竞争力,让蚂蚁稳居国内大模型行业第一梯队,而全系列开源的策略,也让其成为当下AI开源生态中不可忽视的新力量。
回溯百灵家族的整体布局,其演进逻辑清晰可见:并非单一追求参数规模攀升,而是在多模态感知、语言生成机制、深度推理能力与即时响应效率等核心维度上全面布局,构建互为补充、协同进化的模型矩阵。
而站在更宏观的行业视角,Ling 2.5架构的成功,传递出一个重要信号:架构创新仍是大模型演进的关键变量。更高的推理效率、更长的上下文处理、更低的部署成本——这些由架构革新带来的系统性优势,正在重新定义大模型的能力边界。
当技术路线趋于多元,当开源生态持续繁荣,开发者也就拥有了更灵活的工具组合来应对不同场景的挑战。
