轻舟智航重新回归高端市场:L2+车型量产已突破百万大关,城市NOA功能也下放到十万级车型中。
在自动驾驶领域,到2026年,“收敛”一词被广泛认为是行业发展的关键词之一。
技术层面而言,多模态的大模型、数据驱动及强化学习等新兴方法展现出一种阶段性“终局”的特点:统一L2+和L4的技术方案正得到越来越多企业的重视与投资。

对消费者来说,高阶智能驾驶辅助系统的门槛明显降低,现在十万级车型已成为普及的先锋部队,这不再是噱头而是购车时的关键考虑因素之一。
在更专业的自动驾驶行业内,围绕上车及量产展开的竞争中,当年造车新势力经历过的末位淘汰赛再次上演,行业格局初现雏形:一家独大、多家竞争的局面逐渐形成。
一强华为无可争议;而其他强势玩家至少需满足几项关键标准:
轻舟智航近年来的业务突破获得了资本市场的持续认可。

尽管过去低调,但如今轻舟智航已不可能被车企或投资者忽视。
CEO于骞对此进行了如下解析——
技术方面,轻舟核心团队来自Waymo,这可以视为其技术趋势把握的基因基础。
但是,于骞对于Waymo的道路保持了创业者的清醒认识:
在L4小巴时代就探索摆脱规则的方法,并提出基于数据驱动预测规划等核心算法,这些都延续到了当前系统中。
同样,在转向L2、端到端和数据驱动时,轻舟智航没有经历痛苦挣扎或背叛L4技术的嘲笑,而是依靠团队的技术前瞻在最合适的时间点上发光发热。
近期轻舟重新涉足L4业务并进入无人物流领域,这同样得益于其数据驱动体系“一通百通”的特性,在攀登技术高峰的过程中产生了新的成果。
由于轻舟的量产前景可观且盈利转正的可能性日益增大,它不再是一家需要追逐热钱的公司。如果真的追求热门资金流向,则直接讲述机器人故事更为直接有效。

技术成熟后接下来就是落地的问题了:
虽然出身Waymo但于骞将轻舟模式总结为技术与产品并重,从一开始就力求面面俱到,比如“开城”策略和不惜成本的硬件投入,被称作“Alphabet的亲儿子”。
相比之下马斯克没有偶像包袱,完全依据技术第一性原理来配置产品,并率先实现了范式创新——地平线、卓驭及轻舟等公司都不否认曾受其启发。

这种第一性原理同样体现在轻舟的实际落地策略中。
J6M方案能够代表今年“智能驾驶普及”的黄金标准,实现既经济又高效的NOA功能,并可惠及十万级车型。
同时也避免了因成本和算力压缩过度而引发用户对体验与安全底线的质疑担忧。
这使轻舟成为唯一一个既有Waymo的优势又能像特斯拉一样的玩家。

自2019年投入数据驱动,到2021年开始使用国产自主芯片征程,技术及商业上的前瞻性和坚定投资是轻舟再次被关注和信任的关键。
当然还有多年如一日的“韧性”,在有限资源下突破技术工程难题的能力。于骞曾说:“轻舟智航就是自动驾驶赛道中的DeepSeek。”

“自动驾驶领域的DeepSeek”如何理解?
从产品方案来看,轻舟单J6M的L2+方案是唯一的,并且其算力-体验-成本完全符合技术和产业发展的规律。
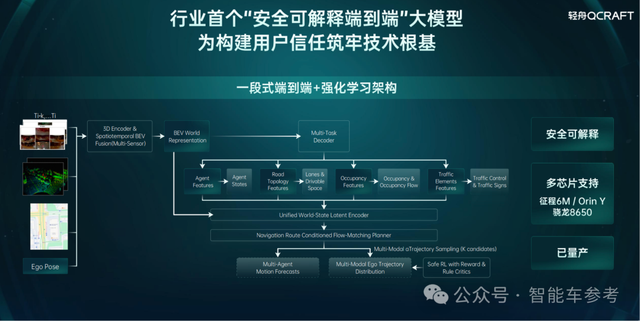
大白话解释就是一分钱一分货,2026年城市NOA和全场景L2“普及”的标准配置是什么样的,轻舟给出了一个样板间。
从研发投入来看,轻舟智航仍然是效益比最高的玩家之一。
自成立以来,公开的融资情况如下:

横向比较其他提供相同“车位到车位”体验的公司,烧钱几乎都是数十亿/年起步。
而每年在AI上投资数十亿元的车企和玩家无一例外都讲述过“内部赛马”、“推倒重来”的故事。
于骞对此给出一个反常识的观点:“资源太多也是一种诅咒”,轻舟的技术前瞻与研发聚焦,某种程度上是不能失败、不敢失败的结果。
相比其他竞争者,现在轻舟智航更关注DeepSeek公司:
这表明DeepSeek抓住了被大多数玩家长期忽视的某些关键点。
技术层面上,于骞特别提到了最近DeepSeek论文中对于模型记忆能力的研究,这实际上解决了大模型资源浪费的问题:模型看似能回答所有问题,但实际上是对同一问题进行反复推理处理。

轻舟也有类似研究,把记忆能力融入到模型里,就像老司机一样记住刚刚经过的路段作为下一段轨迹输出参考,避免“无论路口有没有车都要刹车”的糟糕体验。
这一方法与英伟达近期开源的大推理模型殊途同归。
轻舟自认为可以称作 “自动驾驶赛道DeepSeek”,是因为表现出相同的特性:
当然还有对未来的研究和探索。
在端到端之后,VLA(Vision-Language-Agents)模型被认为是下一代L2+量产的最大技术革新,因为它既能解决端到端的黑盒问题,又能使AI司机具备真正理解场景的能力,这种能力被视为自动驾驶“从2级迈向3级”或“从2级迈向4级”的关键技术之一。
轻舟同样在推进VLA量产体系的研发工作,其系统主要包含三个模块:World Encoder(世界编码器),充分复用轻舟已量产验证的端到端模型能力,建立统一的世界表征;Transformer Decoder(转换器解码器)引入大语言模型同时加入思维链—CoT中间表示让决策不再是“黑盒数值映射”而是结构化推理。

最后是Multi Modality Decoder(多模态解码器),作为世界预测模型的一个生成式模型,通过在行车环境联合分布中找到多个轨迹的最优路径。还通过引入语言监督与Safe RL实现从防错系统向安全优化系统的跃迁。
轻舟VLA体系的最大不同在于突破了“语言仅用于解释”的传统模式,在车机上显示思考过程和语音控制之外,还可以将语言能力作为模型内部决策的依据真正解决Corner case(边界情况)问题。

Multi Modality Decoder 作为一个世界预测模型生成式模型包含对未来交通参与者、道路拓扑变化以及2D和3D世界的建模。
按照于骞的说法,从VLA、世界模型开始自动驾驶公司不再局限于“车”这个领域而是扮演起类似“上帝”的角色为更广阔的现实世界挑战而生:

数据驱动体系一通百通后自然而然打开了通往物理AI时代的大门。
用户层面可能感知不到明显变化,但一级市场已经意识到稀缺性所在:既有技术方案实现盈利无风险且没有被车企、大厂收购控股或估值飞涨——
类似轻舟这样掌握自动驾驶最后一张船票或者说通往物理AI时代“早鸟票”特质的玩家寥寥无几了。
从自身来看,轻舟具体的成绩单是这样的:

加上已经确定的理想Pro车型,今年轻舟智航的高阶NOA辅助驾驶上车,有可能超过一百万辆。
从外部环境上,2025年是自动驾驶赛道残酷的末位淘汰,有昔日明星公司突然倒下,也有当年的技术Leader重回沉默…….最容易直观感知的资本,这一年也大多流向低速物流这样场景简单的赛道。

而轻舟业务突破的同时,仍然不断获得资本认可:

无论此前多么低调,但如今都得看到一个事实,轻舟智航,已经不可能再被车企、资本忽略了。
CEO于骞给出的解析是这样——
从技术上,轻舟核心团队从Waymo而出,这可以看成轻舟智航对技术趋势精准把控的底层基因。
但于骞对Waymo走的路线有保持了创业者罕见的清醒:
L4小巴时代就在探索摆脱规则的方案,当年提出的基于数据驱动的预测规划等等核心算法,也继承在如今的系统中。

换句话说,向L2、端到端、数据驱动转轨,轻舟智航没有痛苦挣扎、没有删库重练、没有背叛嘲讽L4,事实上是核心团队的技术前瞻,在最合适、最紧迫的节点,等到了行业级的底层范式重构,再次发光发热了。
同理,如今轻舟智航业务重回L4,入局无人物流车,也是数据驱动技术体系“一通百通”之后,攀登技术珠峰沿途下的蛋。
毕竟轻舟量产前景可期,盈利转正的悬念越来越小,已经不是一家需要追逐热钱的公司,如果真的奔热钱而去,直接讲机器人的故事会更加直接。
技术通了,那么接下来落地呢?
虽然是从Waymo出来,但于骞将其模式总结为技术、产品同时抓,一开局就要面面俱到,比如“开城”模式和不计成本的硬件投入,所谓“Alphabet的亲儿子”。

但与之相比马斯克丝毫没有“偶像包袱”,完全本着技术第一性原理去配置产品,反而率先走通了范式创新——地平线、卓驭、轻舟等等都不否认曾受到启发。
这样的第一性原理,同样体现在轻舟的落地方案上。
单J6M的方案,能够真正代表今年“智驾平权”的黄金方案,能做到“好用而不贵”的城市NOA功能,可以普惠到10万级车型。
同时又不至于因为太过极致的成本、算力压缩,引起用户对体验和安全底线的质疑担忧。
这也让轻舟成了行业唯一一个既具备Waymo优势,又更像特斯拉的玩家。

2019年就投入数据驱动、2021年就开始投入国产化自主的征程芯片的轻舟智航,技术、商业上的前瞻、坚定投入,是轻舟再次被看见、被相信的核心。
当然,还有数年如一日的“韧性”,在有限资源条件下突破技术工程难题的韧性。
CEO于骞的原话:“轻舟智航就是自动驾驶赛道的DeepSeek。”
“自动驾驶赛道DeepSeek”,如何理解?
产品方案上看,轻舟单J6M的L2+方案是行业唯一,而且算力——体验——成本完全符合技术、产业链发展规律。
大白话解释,一分钱一分货,2026年城市NOA、全场景L2“普及”的标准配置是什么样,轻舟打了个样板间。
而研发投入来看,轻舟智航仍然是效费比最高的玩家之一。
2019年成立以来,公开可查轻舟智航的融资情况就是这些:
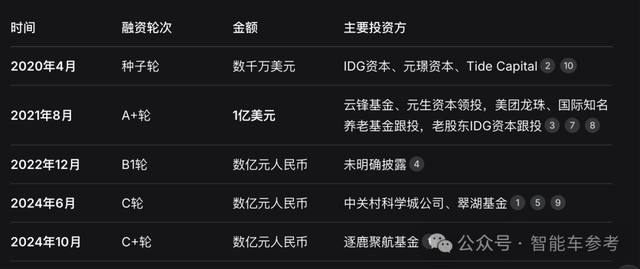
横向对比拿出相同“车位到车位”体验的玩家,烧钱几乎是数十亿/年起步。
而每年在AI上投数十亿的车企、玩家,几乎无一例外都讲述过“内部赛马”、“推倒重来”的故事。

于骞对此给出了一个反常识的观察:“资源太多,反而是一种诅咒”,轻舟的技术前瞻、研发聚焦,某种程度也是不能失败、不敢失败的结果。
不过相比友商,现在轻舟智航给予关注最多的AI公司,反而是DeepSeek:
这就说明DeepSeek抓住了某些极为关键、但却被大多数玩家长期忽视的东西。
体现在技术上,于骞特别提到了最近DeepSeek论文中对于模型记忆能力的探索,实际上是解决了大模型的资源浪费问题:模型看似对某类问题对答如流形成了一套机制,但实际上背后是对相同问题进行一次次反复推理。

轻舟智航也有类似的研究,把记忆能力融入模型,像老司机一样记住刚刚开过的路段,作为下一段轨迹输出的参考,避免“无论路口有没有车都要刹车”的糟糕体验。
这实际上又和英伟达前不久开源的推理大模型,殊途同归了。
轻舟自认为可以称得上 “自动驾驶赛道DeepSeek”,是因为表现出了相同的特性:
当然还有对未来的探索。
端到端之后,VLA模型被认为是下一代量产L2+的最大技术革新,因为它既能解决端到端的黑盒问题,又能让AI司机具备真正对场景的认知理解能力,而这样的理解能力也被视为自动驾驶“破2到3”、“破2到4”的关键技术之一。
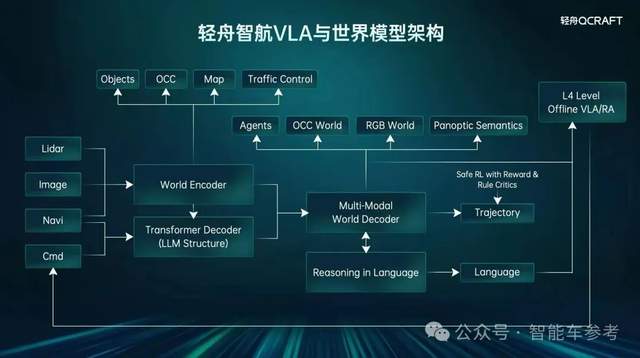
轻舟同样也在推进比如最新的VLA量产体系,其中既有系统主要有三个大的模块,首先World Encoder,充分复用轻舟已量产验证的端到端模型能力,建立统一世界表征;接着,是又Transformer Decoder,除引入大语言模型外,还加入了思维链——CoT中间表示,让决策不再是“黑盒数值映射”,而是结构化推理。
最后是Multi Modality Decoder,作为世界预测模型的一个生成式模型,通过在行车环境的联合分布中生成的多个轨迹当中找到一个最优轨迹。还通过引入语言监督与Safe RL,让安全监督与知识内生到模型里,实现从“防错系统”向“安全优化系统”的跃迁。
轻舟VLA体系的最大不同,是突破了“语言仅用于解释”的传统,除了在车机上显示思考过程和语音控车之外,语言能力完全可以作为模型内部决策的条件依据,真正解决Corner case。
有Multi Modality Decoder,作为世界预测模型的一个生成式模型,包含了对未来世界的动态演化能力,包含对未来交通参与者、道路拓扑的变化以及2D和3D世界的建模。

按照于骞的说法,从VLA、世界模型开始,自动驾驶公司已经不再局限于“车”这个领域,实际开始扮演“上帝”的角色,比如轻舟新一代大模型完全为更广阔现实世界挑战而生:
数据驱动体系一通百通后,自然而然打开了通往物理AI时代的大门。
用户这一层感知可能不明显,但一级市场已然意识到了稀缺性所在:有技术有方案,实现盈利无风险,且没有被车企、大厂收购控股、估值还没有一飞冲天——
如同轻舟一样手握自动驾驶最后一张船票,或者说通往物理AI时代“早鸟票”特质的玩家,寥寥无几了。