
当前时间序列预测模型普遍采用基于极大似然估计的方法,使用 MSE 作为损失函数。然而,在标签序列存在自相关性的情况下,这种方法会导致偏差。
最近,北京大学林宙辰教授团队提出了一种新的方法,即将时间序列预测问题转化为条件分布对齐的问题,并引入了一个新的损失函数来最小化预测值和实际标签之间的 Wasserstein 距离。这一创新不仅保证了训练过程的无偏性,还充分考虑到了自相关性的几何结构。
这项工作为利用最优传输等方法解决时间序列预测问题提供了全新的视角和理论依据。

- 该研究论文标题为“DistDF: Time-series Forecasting Needs Joint-distribution Wasserstein Alignment”。
- 研究团队成员来自小红书、北京大学、浙江大学、上海财经大学以及松鼠 AI 等机构。
- 相关代码可在 GitHub 上获取:https://github.com/Master-PLC/DistDF
1. 问题分析:标签中的自相关性
构建有效的预测模型需要解决两个核心问题,即选择合适的架构和正确的训练方法。在过去十年里,研究者们在架构创新方面投入了大量精力,如 Transformer、线性模型以及图神经网络等相继登场。然而,很少有人质疑时间序列数据中所用损失函数的适用性。
目前主流的时间序列预测方法采用直接预测范式(Direct Forecast, DF),该方法接收一段历史观测数据,并通过神经网络提取特征进行未来 T 步的并行预测。相比传统的迭代预测,DF 方法在训练效率上具有显著优势。
在损失函数的选择方面,大多数研究都采用了时序均方误差(TMSE)。
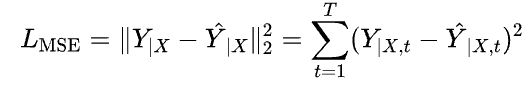




2. DistDF:基于联合分布对齐的新型训练方法
DistDF 团队注意到,在训练预测模型的过程中,其本质是让模型生成的条件分布尽可能接近真实标签。因此,DistDF 方法不再依赖传统的极大似然估计,而是直接最小化两个条件分布之间的 Wasserstein 距离,从而避免了自相关性带来的似然估计偏差问题。
2.1 条件分布对齐到联合分布对齐的转化


研究进一步指出,通过最优传输领域的理论推导可以证明:联合分布的 Wasserstein 距离是条件分布 Wasserstein 距离期望的一个上限。因此,最小化历史 - 预测联合分布与历史 - 标签联合分布之间的 Wasserstein 距离能够有效实现对齐任务。
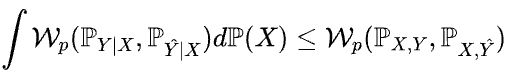
此外,这种方法还能通过采集全体数据集中的样本大大增加用于估计分布距离的样本数量,从而提高估算的可靠性。
2.2 基于 Bures-Wasserstein 距离的新损失函数
直接计算 Wasserstein 距离需要解决大规模最优传输问题,在大批量训练时会带来较大的计算负担。幸运的是,基于高斯分布假设下联合分布间的 Wasserstein 距离可以解析地表示为均值和协方差之间的距离之和。
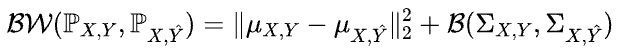

DistDF 的具体实现步骤如下:


DistDF 是一种与模型无关的损失函数设计方法,适用于各类预测模型。
3. 实验结果
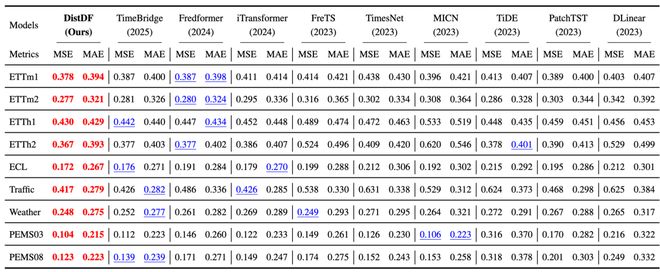
实验表明,DistDF 可以显著提高预测性能。例如,在 ECL 数据集上,DistDF 将 iTransformer 的 MSE 降低了 2.7%。这些改进主要归功于 DistDF 能够处理标签中的自相关性并通过条件分布对齐来提升模型的预测能力。
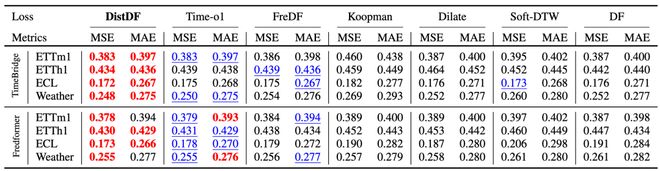
相比其他损失函数,DistDF 在性能上有显著优势。FreDF 和 Time-o1 尽管减少了似然估计偏差并提高了性能,但仍然存在残差偏差;而 DistDF 通过最小化条件分布之间的距离实现了无偏对齐,从而达到了最佳效果。
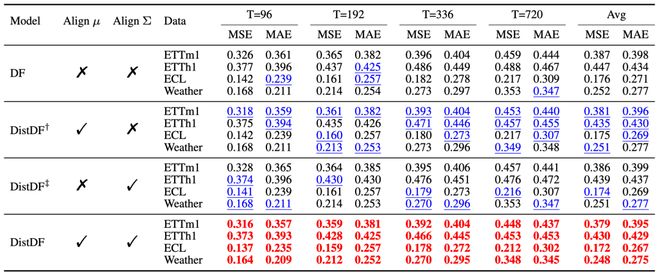
论文还进行了消融实验来研究均值和协方差对齐对于损失函数表现的影响。结果显示:单独进行均值或协方差的对齐相比于 DF 都有所改进,而两者结合则取得了最优结果,展示了它们之间的协同效应。

视觉化分析显示,DistDF 生成的预测序列与真实标签序列之间具有更高的拟合度,并且能够有效抑制噪声和异常波动;对于困难样本的外推能力也更强。

论文还测试了 DistDF 在不同神经网络架构上的表现,包括 TimeBridge、FredFormer、iTransformer 和 FreTS 等,证明其与模型无关特性:能够显著提升大多数主流预测模型的精度。
4. 结论
本文深入探讨了基于极大似然估计的时间序列预测方法存在的偏差问题,并提出了一种新的训练框架 DistDF。该框架直接通过对齐条件分布来改进预测模型。考虑到在有限样本下难以直接估计条件分布间的距离,论文进一步转向联合分布对齐并提供了理论依据。大量实验表明,DistDF 在各种数据集和模型中均表现出色。
本研究不仅强调了损失函数设计的重要性,并揭示了利用分布对齐技术来改进时间序列预测的潜力,为迁移学习领域自适应生成模型等领域的应用奠定了理论基础并提供了实践思路。
5. 作者介绍

论文通讯作者李昊轩现任职于北京大学助理研究员,在清华大学逻辑学研究中心和牛津大学担任研究员。其研究兴趣在于因果推断及大模型逻辑推理,以第一或通讯作者身份发表 CCF-A 类论文 50 余篇,谷歌学术引用超过 1000 次,并拥有国家发明专利授权 17 项;研究成果被麻省理工科技评论、人民日报和中国人工智能学会等媒体广泛报道。

论文另一位通讯作者林宙辰博士现任北京大学智能学院教授及通用人工智能全国重点实验室成员。他的研究领域涵盖机器学习与数值优化,已发表论文 360 余篇,谷歌学术引用超过 42,000 次;曾多次担任 CVPR、NeurIPS 和 ICML 等会议的 Senior Area Chair,并且是 ICML Board Member。本项研究得到了北京市科学技术委员会和中关村科技园区管理委员会的支持,在此表示诚挚感谢。