今天,云知声正式发布了Unisound U1-OCR 文档智能基础大模型。
作为首个工业级文档处理平台的基础模型,它凭借“性能领先、值得信赖、易于使用、高效部署和高度适配”五大核心优势,突破了传统文档处理的限制,并确立了行业新标准。
文档智能是指运用人工智能技术自动读取并理解文档影像内容,进行分类及关键信息提取。
传统的OCR解决方案(1.0版)以CRNN为代表,只能识别文字。新一代方案(2.0版),如VLM,则具备端到端的布局理解和文字识别能力。
Unisound U1-OCR正式开启了OCR 3.0时代——在理解文档排版的基础上,进一步分析深层语义,并实现自动分类和业务级信息抽取,完成了从“字符感知”到“文档认知”的重要转变。
这款模型达到了国际顶尖水平,在理解和处理复杂文档方面超越了传统方法的局限性。它不仅能识别文字,还能像人类专家一样理解复杂的布局结构。
为了适应OCR 3.0时代对业务级信息抽取的新需求,Unisound U1-OCR采用了ViT和LLM架构,并使用NaViT进行视觉编码,实现了文档分辨率的动态处理。模型参数规模达到3B级别,既保证了计算效率又提升了深层语义的理解能力。
此外,该模型还提出了一些创新点:
首先,它能够“先理解结构再阅读内容”。与传统方法不同,Unisound U1-OCR采用了“语义驱动+动态聚焦”的策略。这种新的方式模仿了人类的阅读习惯:首先梳理文档的层级关系,然后按需提取信息。
该模型可以自动构建文档的“语义地图”,精准识别标题、图表与正文之间的从属关系,在极端排版混乱的情况下仍然能够条理清晰地提取信息。
其次,它具备优秀的“空间感知力”。通过强化空间对齐模块,它可以利用文字在页面上的位置信息来理解元素间的布局。结合动态分辨率技术,无论是密集表格还是图文混排,都能精准还原文档结构,并有效解决了以往模型的定位问题。
此外,该模型采用了Multi-Token Prediction(MTP)技术,在预测当前Token时会考虑未来多个Token的概率分布,这显著提升了长文档逻辑连贯性。
与全任务强化学习策略相结合,提高了对版式结构的整体预见性,并在推理阶段将生成效率提升了80%以上。
在训练过程中采用了多任务协同强化训练方案,实现了文档还原、分类和信息抽取的深度整合。这种优化围绕“语义+坐标”目标进行,针对坐标回溯精度进行了专项强化,确保了输出结果的有效性,并通过多档位分辨率扰动与Mask采样策略提升了模型对多种场景的理解能力。
凭借这些创新点,在多项权威测试中,Unisound U1-OCR均取得了业界顶尖的表现,实现了从“文字识别”到“文档理解”的跨越。
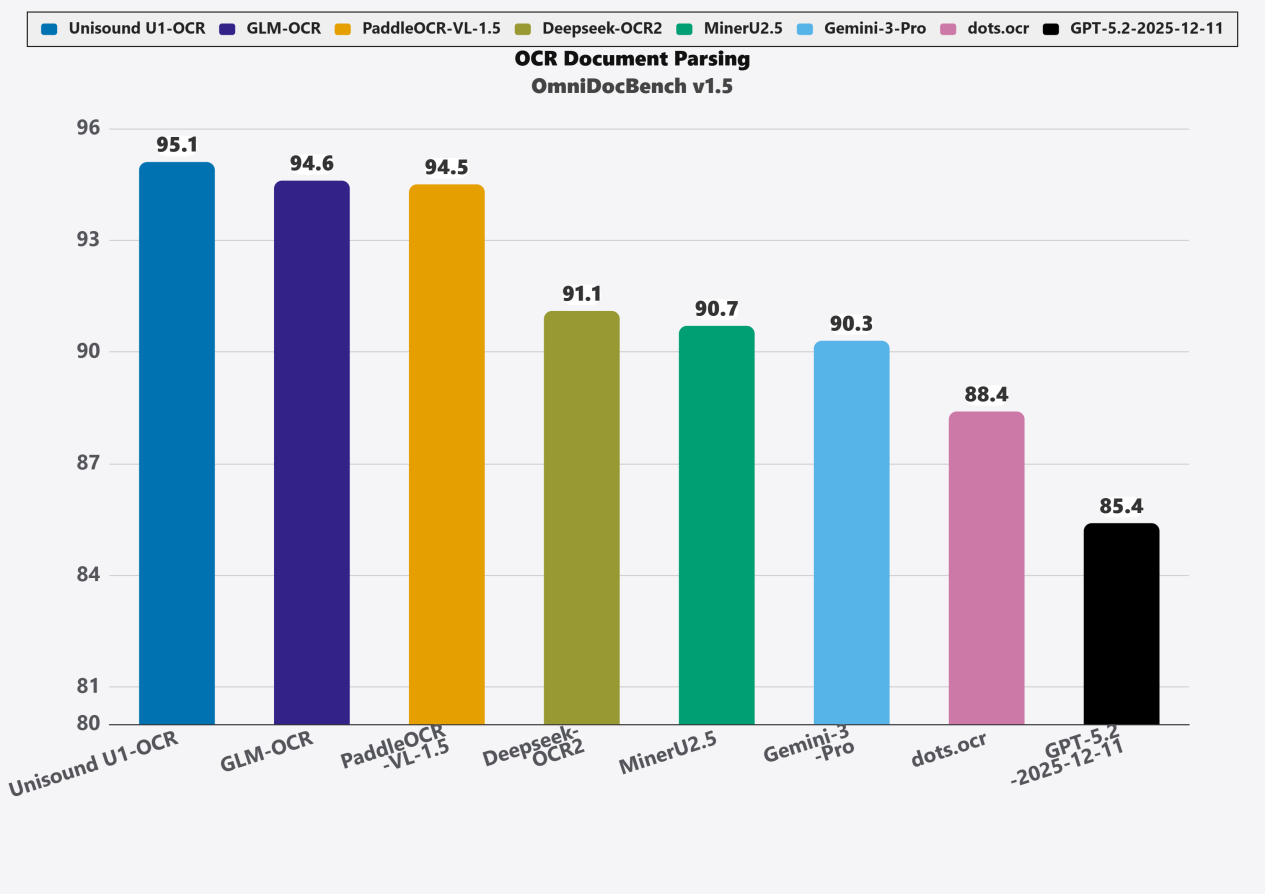
在OmniDocBench V1.5评估中,其得分达到95.1分,超过了GLM-OCR、Deepseek-OCR2等主流模型。这标志着精度和泛化能力的双重突破。
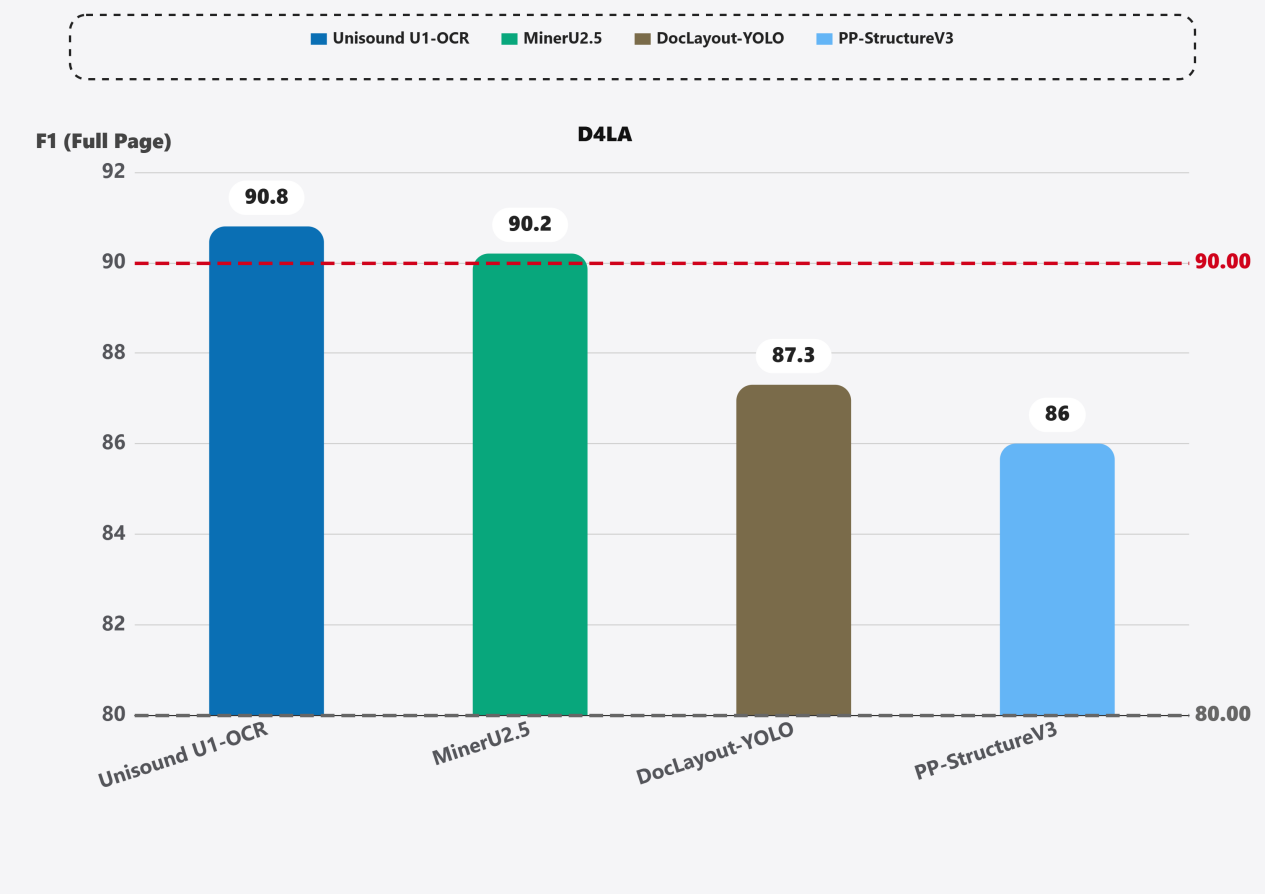
在D4LA评测中,F1分数为90.8,在学术论文和财务报表等多种复杂文档解析方面大幅领先DocLayout-YOLO(87.3)及PP-StructureV3(86.0)。无需微调即可实现高精度解析。
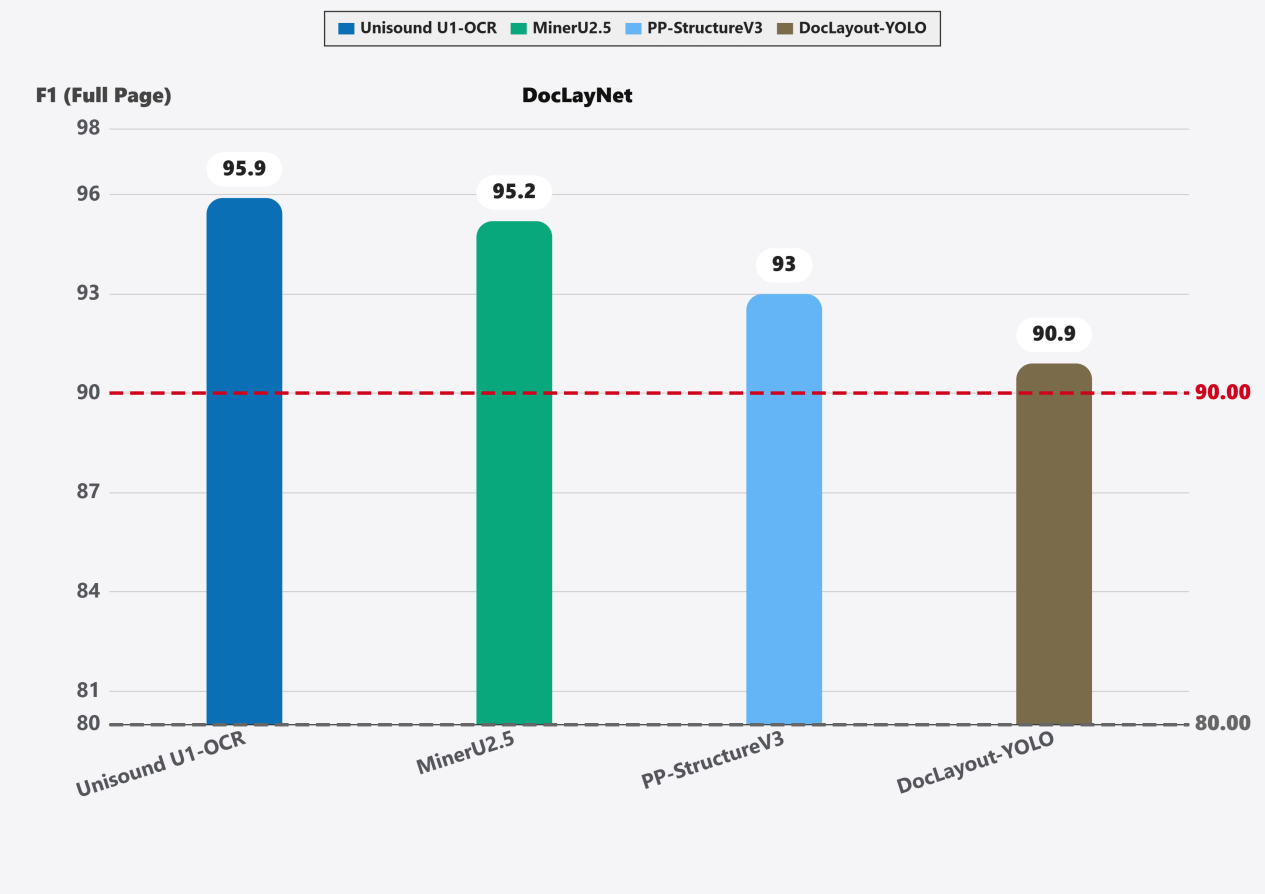
DocLayNet测试中的F1分数达到95.9,超越了MinerU 2.5和PP-StructureV3等模型,在表格识别、跨页关联和微小文本检测等方面表现出色且鲁棒性强。
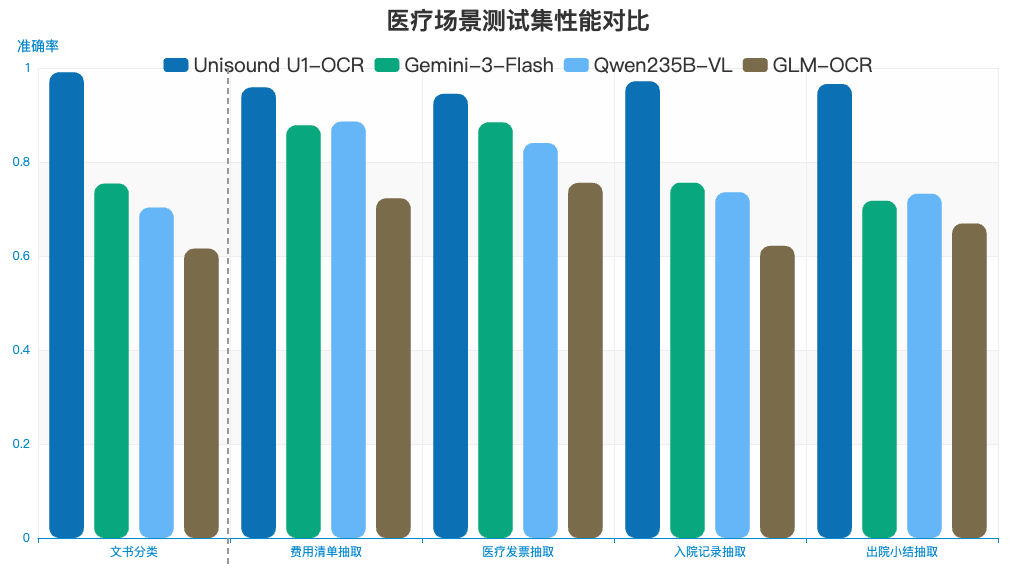
内部业务测试中(如图4),其信息抽取与文书分类能力优于多个主要的通用商业及开源模型,特别是在医疗记录等具体应用领域优势明显。
尤其是在处理入院和出院小结这类复杂文档时,Unisound U1-OCR以3B参数规模超越了更大规模的通用VLM,在评测中表现出色。
与较小尺寸的解析模型相比,得益于多项创新技术的应用,该模型在业务级信息抽取等深层语义理解方面表现更佳。
作为开启OCR 3.0时代的文档智能基础大模型,Unisound U1-OCR不仅在通用测试中屡获第一,还结合了工业场景的实际需求,打造了四大核心能力,实现了从“读懂”到“执行”的业务落地。
可信可验:精准定位和证据链构建
模型独创了“坐标-文本-语义”融合架构,实现像素级别的精确位置标记,并建立了完整的证据链条。这使得文档处理结果更加透明、可追溯,在技术层面上确保了可信度。
例如在企业审核场景中,审核人员点击抽取结果即可实时高亮定位原始位置,这种“人机协同”的闭环大幅缩短了审核时间并降低了人工漏检率。
开箱即用:业务融合
在特定领域如医保结算单中的自付费用规则或合同金额大小写校验等需要专业知识的场景下,Unisound U1-OCR能够基于业务逻辑进行多字段关联验证。在内部测试中对50多种常见文书分类准确率超过99%。
模型支持私有化和离线部署,在无网络环境下依然可以稳定运行,并能满足政务、医疗等高安全要求行业的数据隐私保护需求。
高效部署,安全可控
通过版面级并行解码与多Token预测架构优化,处理一份十多页的文档仅需数秒即可完成。高效的文档处理能力让工业级智能文档变得触手可及。
强大适应性:应对复杂场景
Unisound U1-OCR能够应对非标准拍照、文档弯曲模糊等极端情况,确保在任何环境中都能保持高精度的性能表现。这种对各种复杂布局的支持使其适用于企业的实际业务需求。
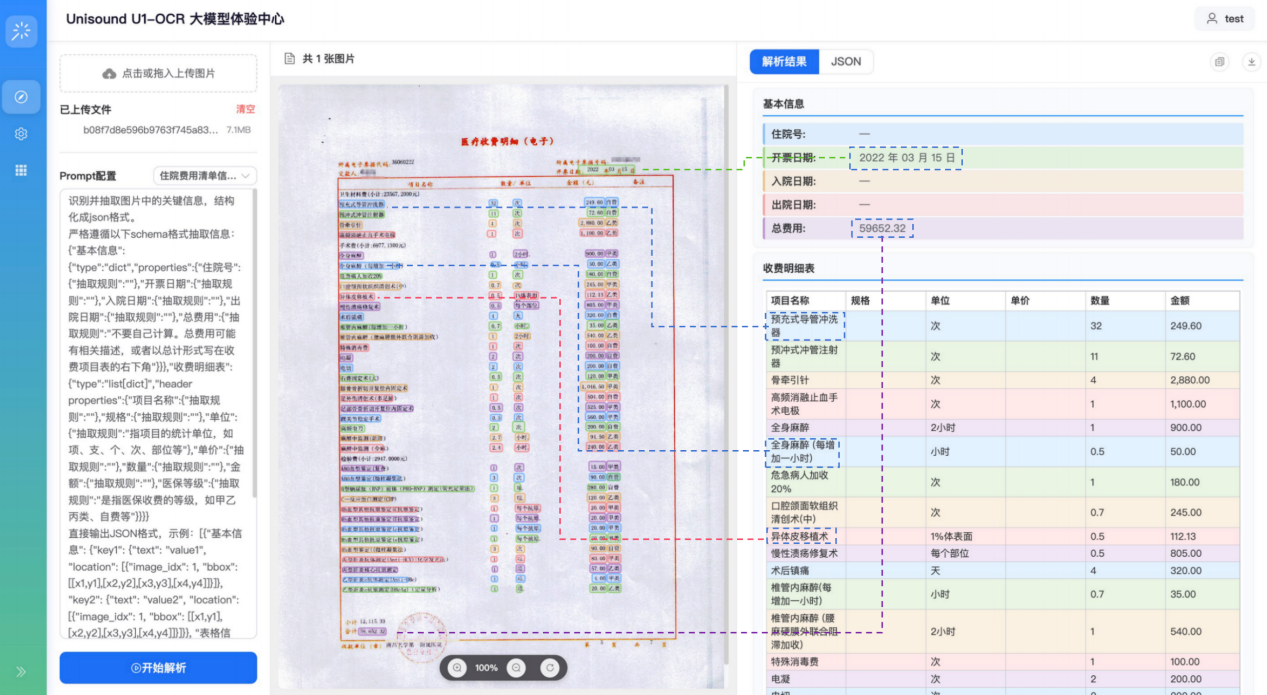
在医疗费用清单抽取中,模型能自动理解不同医院间的语义差异,并将描述统一对齐映射至数据库字段,实现结果直接入库。
同时支持像素级别的坐标回溯,通过不同颜色高亮显示抽取内容与原图位置对应关系(如图所示),确保数据准确录入的同时提升业务效率。
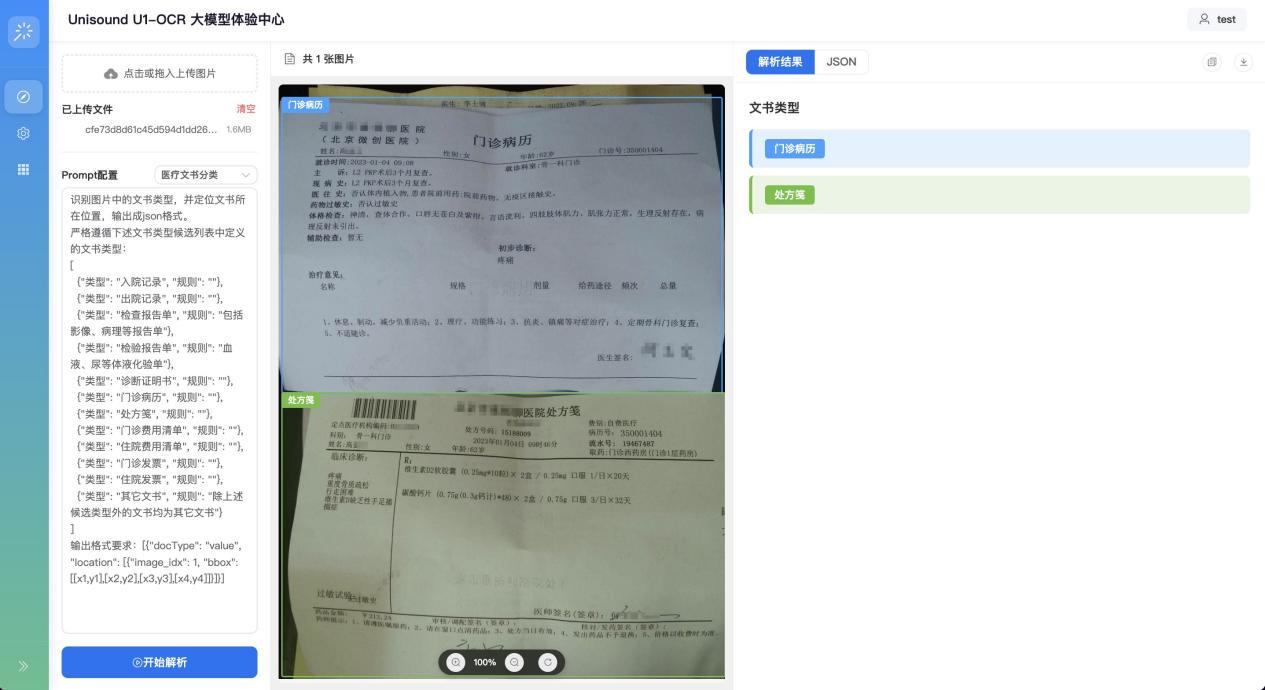
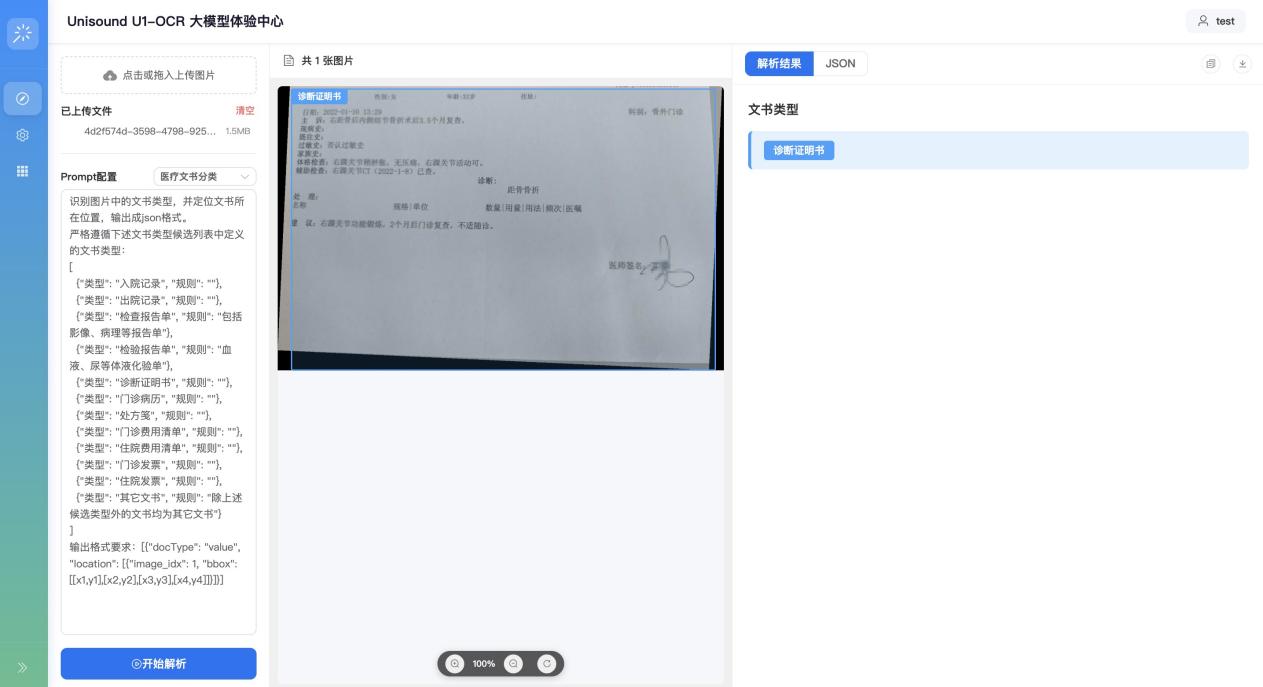
模型可以自动识别和分割包含病历、处方等混叠文件的单据,并一键完成自动化归档和提取。让处理海量复杂文档变得简单高效。
即使面对遮挡或内容缺失的情况,模型仍能根据深层语义准确判定类别,显著提升了自动化处理的成功率。
在解析报纸、期刊等多栏穿插的复杂版面时,Unisound U1-OCR能够像人一样结合上下文和排版逻辑自动判断段落关系,提高阅读理解能力。
通过智能“图像净化”功能消除水印干扰并校正扭曲页面布局,无论原图多么杂乱都能输出布局规整、内容清晰的标准化文档。
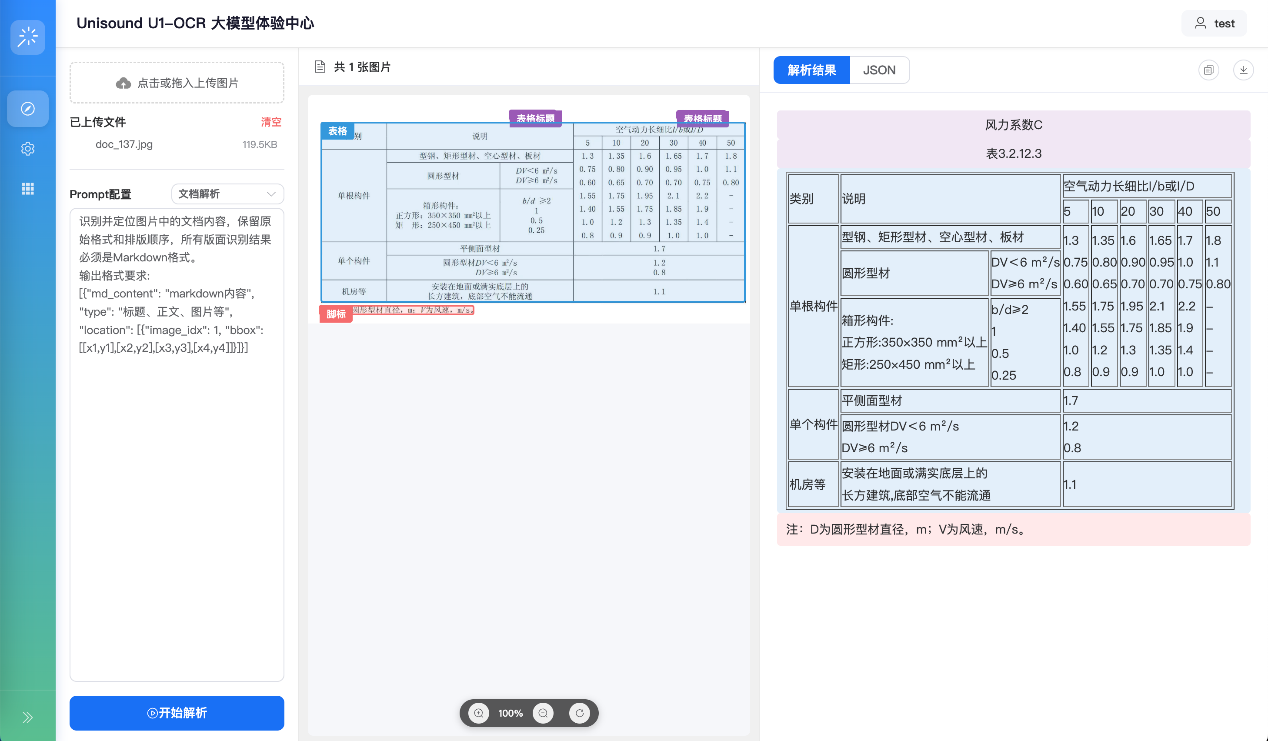
面对跨行、跨列及嵌套表格时,模型不仅能精准解析内容还能完整保留原始结构和逻辑关系。无需二次调整即可直接使用,适用于统计报表或工程图纸等各类文档。
Unisound U1-OCR开启的OCR 3.0时代标志着AI从单纯识别文字向理解业务逻辑的重大转变。
这不仅是文档智能领域的革新,也是云知声向AGI迈进的重要一步。团队将以此为基础,赋予机器自主推理与证据溯源能力,推动人工智能技术的发展。
展望未来,云知声致力于构建能够像人类一样思考并解决复杂问题的通用智能体,让每一份文档都成为通向AGI之路的知识阶梯。

案例5:针对满屏水印与倾斜排版,模型可自动执行“图像净化”——智能消除水印干扰,精准校正扭曲版面。
无论原图多杂乱,都能输出布局规整、内容清晰的标准化文档,为后续识别奠定干净基础,彻底消除干扰隐患。
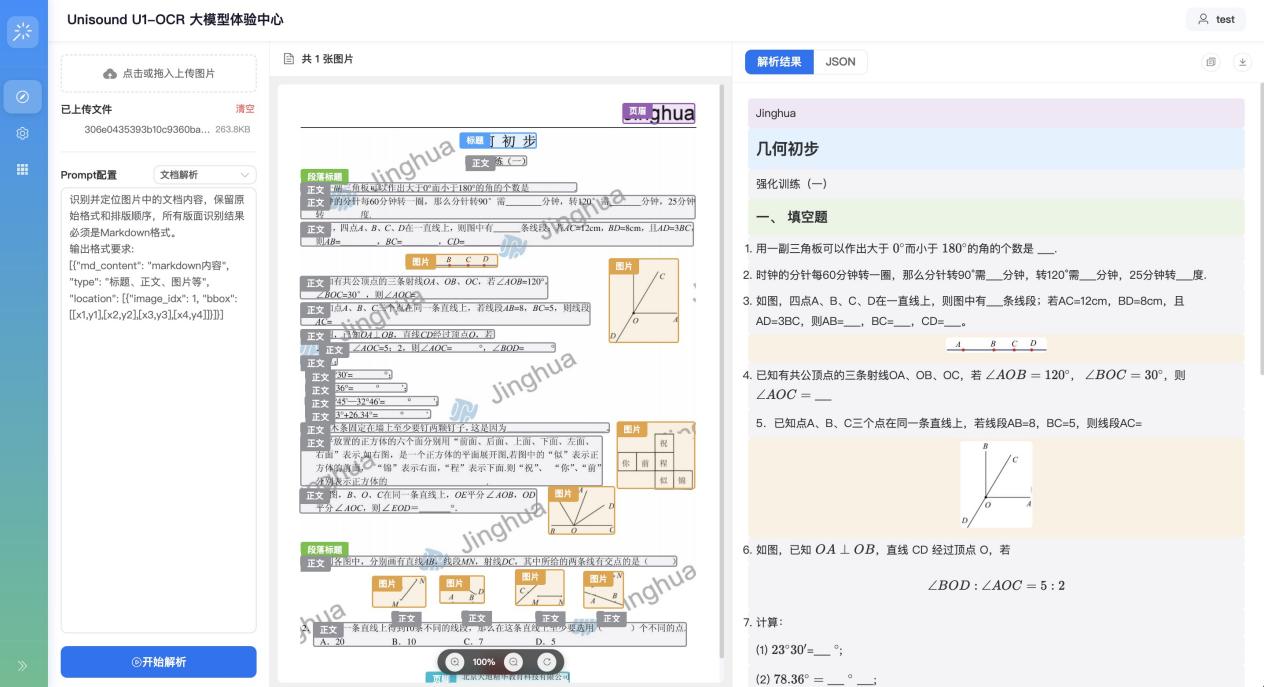
案例6: 面对跨行、跨列及嵌套的复杂表格,模型不仅能精准解析内容,更能完整保留原始行列结构与逻辑关系。输出结果直接可用、无需二次调整,无论是统计报表还是工程图纸都能轻松解析。
Unisound U1-OCR开启OCR 3.0时代,标志着AI从单纯“识字”跃迁至“理解业务逻辑”。
这不仅是文档智能的革新,更是云知声迈向AGI的关键一步。团队将以多模态文档为知识入口,赋予机器自主推理与证据溯源能力,推动AI从感知走向认知。
未来,云知声期待构建能像人类一样阅读、思考并解决复杂问题的通用智能体,让每一份文档都成为通往AGI的智慧阶梯。