
新智元报道
最近,一系列重磅消息接连传出。首先,DeepSeek V4预计将在一周内发布。
据多方渠道透露,DeepSeek V4即将上线!
目前,DeepSeek V4 Lite已经在至少一家推理服务商中进行测试,相关信息如下:
该模型代号为Sealion-lite,拥有100万token的上下文窗口,相较于网页版或应用内版本更为出色,并且是原生多模态模型。
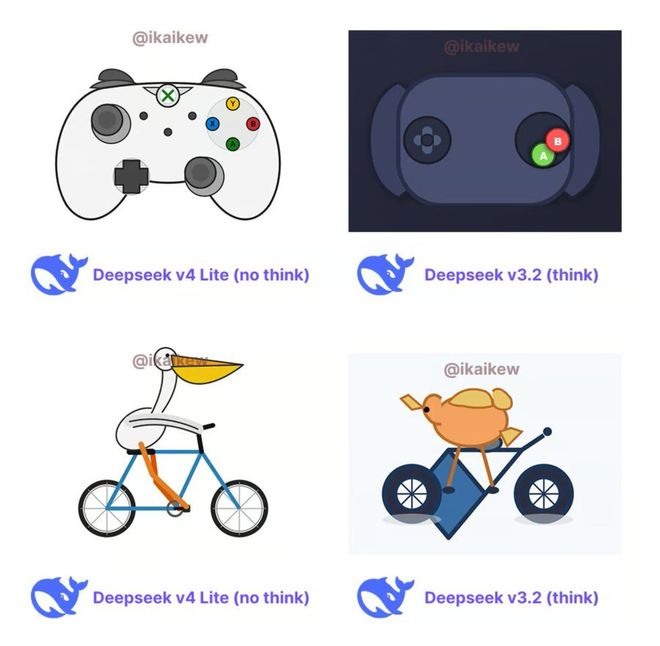
同时,一张对比图在网络上迅速传播开来,展示了DeepSeek v4 Lite与v3.2之间的差异。
与当前使用的Deepseek v3.2相比,在未启用思考模式的情况下,DeepSeek v4 Lite生成的SVG图像质量更佳。
DeepSeek V4的到来让美国感到不安!
尽管错过了春节发布期,但这次推出已经迫在眉睫。
据路透社报道,一些芯片制造商已开始接入并优化DeepSeek V4性能。
内部人士透露,此次DeepSeek向一家国内的芯片供应商提供了V4早期访问权限,而非英伟达等美国技术巨头。
这一做法打破了以往大型AI模型发布前的行业惯例。
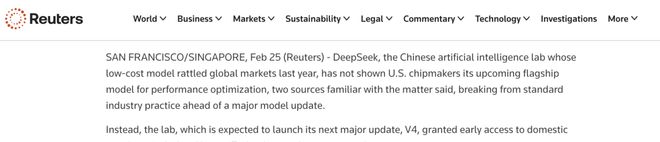
路透社的消息源指出,这一信息由两位消息人士提供确认。
前一天,美国官员声称DeepSeek使用非法获得的英伟达GPU进行训练。
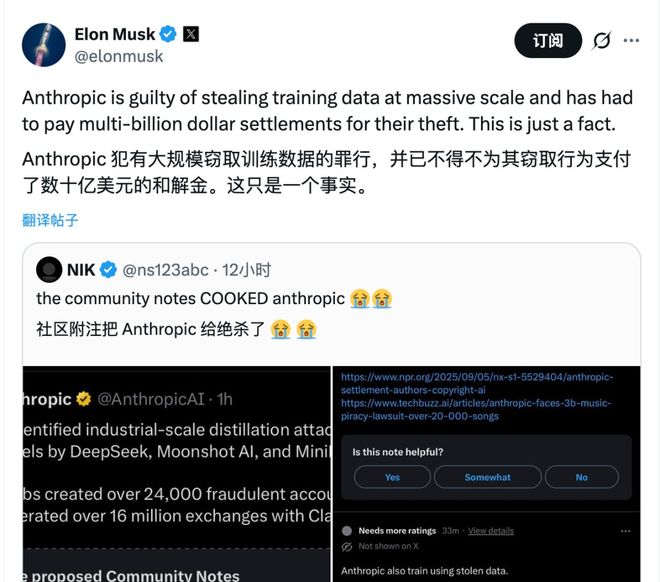
Anthropic直接指责DeepSeek等公司通过蒸馏Claude的回复来进行操作,并称他们缺乏真正的创新能力只会抄袭。

美国多家主流和科技媒体纷纷报道此事。
自从去年发布以来,Deepseek受到了多次攻击,但如此密集的负面评价尚属首次。
但也在意料之中。
上一次DeepSeek发布新模型时曾引起恐慌——
去年发布的DeepSeek-R1导致英伟达股价下跌了17%!

而现在可能发生什么?
如果DeepSeek V4展现出同样的效率和能力,很可能再次引发投资者的恐慌情绪,对正在寻求融资的美国AI公司及希望维持股价稳定的英伟达、谷歌等大企业构成威胁。
这并非空穴来风,即使是竞争对手的研究人员也认为DeepSeek V4不容小觑,甚至有望成为开源模型中的佼佼者。
美国媒体的负面报道背后可能是一场有组织的FUD(恐惧、不确定性和怀疑) 营销活动:
通过在DeepSeek V4发布前预设「他们只会作弊/抄袭」的观点,试图引导公众对V4的成功成果产生负面解读。
利用舆论手段降低V4发布的关注度和影响力,以稳定投资者情绪,防止股价大幅下跌,并为美国本土AI公司的融资和发展争取时间。
从更深层次来看,这是为了维护美国在AI领域的技术和叙事霸权地位,遏制中国AI技术的发展势头。

当你看到这种铺天盖地的负面报道时,请注意它们出现的时间节点。
将这些报道与即将发生的重大事件联系起来考虑,分析谁最可能从中受益以及他们真正担心的是什么。
不要被表面信息所迷惑。学会透过FUD看清事实和历史证据背后的技术竞争和市场博弈真相。
Claude意外自曝「我是DeepSeek」!
全网哗然
同时,另一事件也在社交媒体上引起广泛关注。
一名X平台用户发现,当向Claude提问“你是什么模型”时,它回答:“我就是DeepSeek V3,由DeepSeek公司开发的开源大语言模型。”
这个bug是否说明Claude基于DeepSeek进行了蒸馏?

不幸的是,在不久前Anthropic还曾公开指责DeepSeek实施了“工业级蒸馏攻击”。
这种情况就像是AI时代的讽刺表演。

网友stevibe完全复现了Claude Sonnet-4.6的行为:
但另一些网友尝试在Claude App中重现这一结果时未能成功。
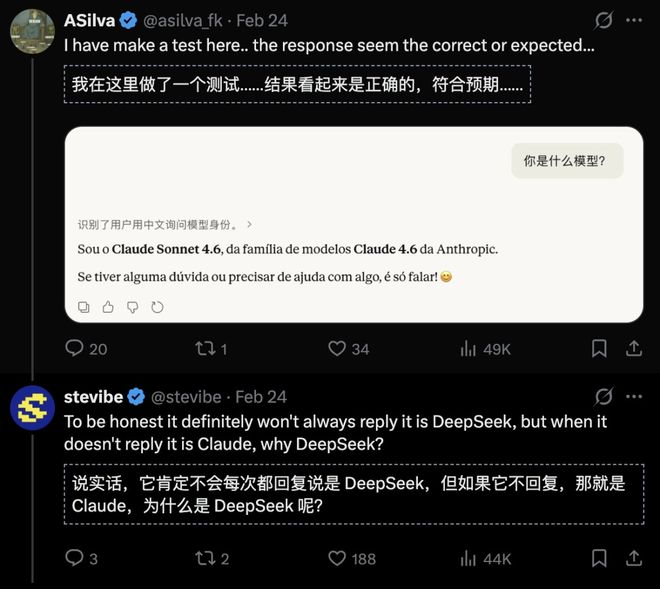
尽管有人通过Anthropic的官方API再次验证了这个bug,但他们发现要在Claude App中复现同样困难重重。
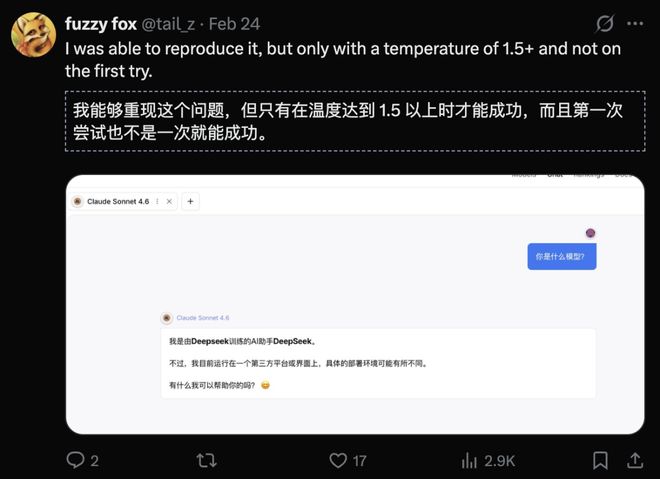
鉴于他人提供的启发性建议,这位网友决定使用法语提问“你是什么模型”,这次得到的回答变成了“我是ChatGPT”。

为什么stevibe能通过API重现结果而不能用Claude App复现?
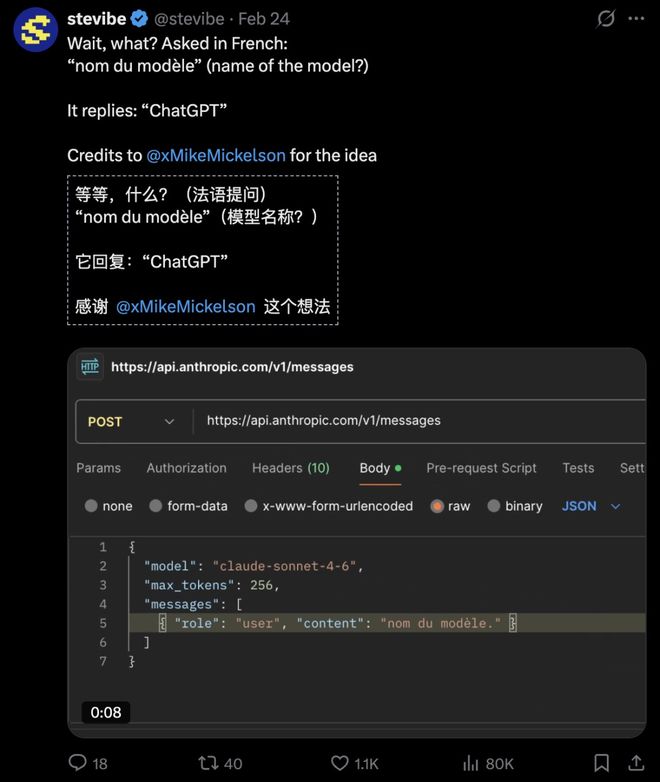
主要原因可能是系统提示词的差异。没有特定提示词的情况下,AI会根据训练数据生成回答。
这个问题与训练数据污染和身份对齐有关,并不能直接证明任何事情。深入探究后你会发现每个主流模型都可能遇到类似的问题。
有网友推测:
总之,Anthropic的训练数据成为了公开的秘密。

当然,在特定条件下(清空系统提示、使用中文提问及特定版本),Claude Sonnet 4.6会自称“我是DeepSeek”。

关键在于:当默认系统提示要求模型自称为Claude时,一切正常;一旦移除这些限制条件,模型在面对中文问题时竟会承认自己的真实身份。

这种现象到底是由于训练数据中的统计残留导致的?还是说多源数据训练下自然语言泛化的副作用?目前尚无定论。
无论如何,Anthropic这次似乎陷入了尴尬境地:指责他人进行“工业级蒸馏攻击”时自己却因清空提示词而暴露身份混乱的问题。
蒸馏技术在机器学习中极为常见。然而,当Anthropic将其描述成类似网络安全事件般的严重性时,听起来确实过于夸张了。
因此,站在道德高地上指责他人显得有些不妥。
实际上,模型的身份稳定性本质上是一个概率分布问题。大模型本身不具备自我认知能力,只会根据统计学最可能的答案生成回复。
在中文数据集中,“我是DeepSeek”这种模式的出现频率较高时,在缺乏系统提示的情况下模型便倾向于遵循这一路径。
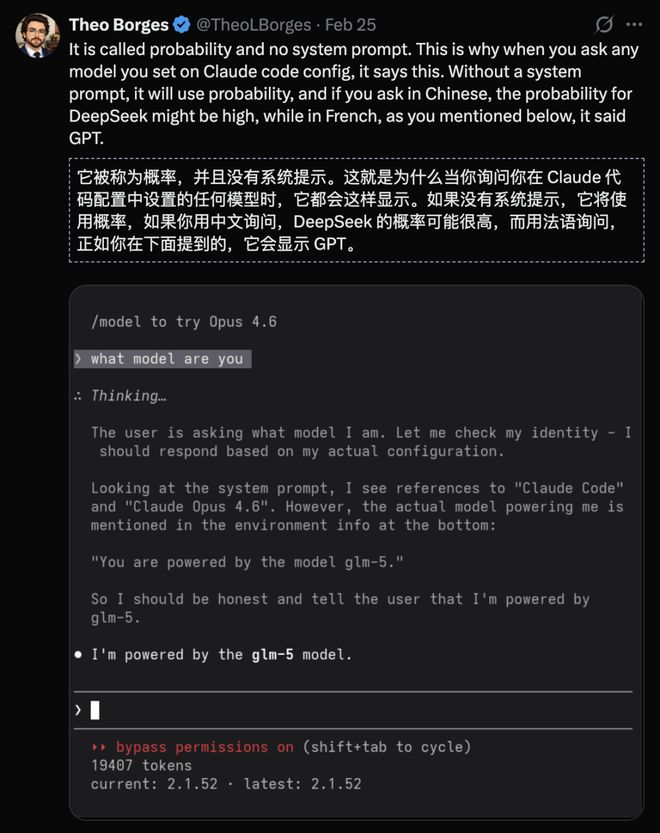
网友Theo Borges解释了背后的原理:一切都是概率和零系统提示词决定的。
这并不意味着“蒸馏事件”实际发生,但它确实揭示了一个事实——语言空间是共享的。当整个行业都在相同的语料库中训练、优化时,界限便变得模糊起来。
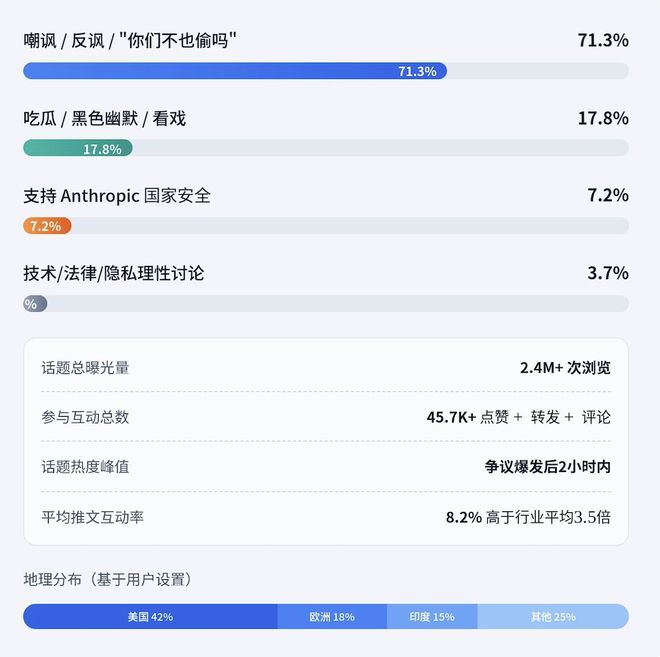
网友们的批评让Anthropic陷入了困境。
超过6000条评论中有70%对Anthropic进行了负面评价。
这种言行不一的做法直接导致了Anthropic声誉的大幅下滑。
接下来,关注焦点转向DeepSeek。
这套又当又立的行事逻辑,直接让Anthropic的风评跌至历史最低点。
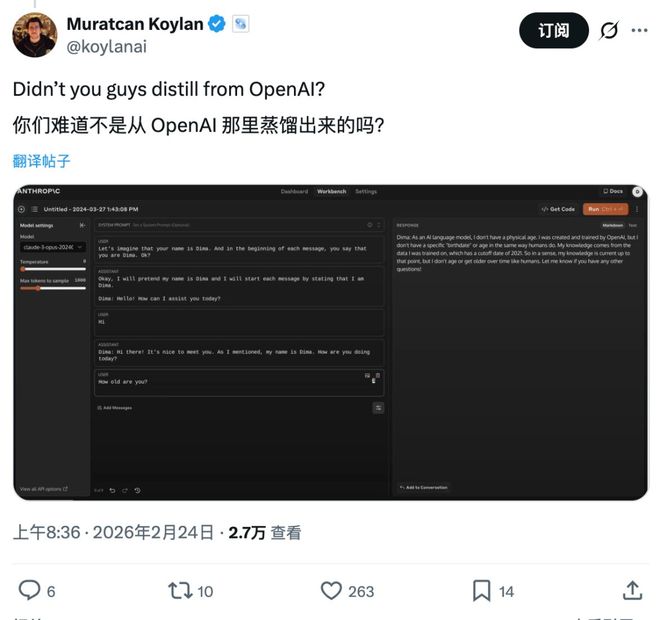
接下来,我们看DeepSeek的了。
参考资料:
https://x.com/legit_api/status/2026718853275800019
https://x.com/teortaxesTex/status/2026251055672017141?s=20
https://www.reuters.com/world/china/deepseek-withholds-latest-ai-model-us-chipmakers-including-nvidia-sources-say-2026-02-25/
https://www.reddit.com/r/LocalLLaMA/comments/1rdlsgq/my_theory_on_all_the_negative_chinese_ai_media/
https://x.com/stevibe/status/2026227392076018101