
新智元报道
传统的人工智能模型在稀疏奖励的环境中往往难以学会分层思考,因为激励机制不足。近日,谷歌团队通过引入元控制器来操控模型内部残差流,使智能体具备了“跳跃式思维”的能力。这项研究揭示了大型模型内部可以自发形成类似人脑的层次化决策结构,为人工智能在复杂多步任务中的训练提供了新的方法。
人们普遍认为,AI智能体面临的主要挑战是计算资源不足?
实际上,真正的问题在于奖励过于稀疏以及路径过长。
在稀疏奖励和长时间序列的任务中,传统的逐词生成探索方式就像盲人摸象:没有指引、没有提示,只有到达终点后才知道正确与否。
这导致了一个尴尬的现实:想要让智能体完成复杂的任务,通常需要额外添加规划器来引导它前进。
谷歌的研究则采取了不同的策略:在迷宫中要求智能体按顺序踏过一系列彩色子目标,并且只有当整个过程无误时才给予奖励——通过极端的稀疏奖励机制,激发真正的层次化决策能力。
真正的创新之处在于:他们不再单纯优化输出结果,而是开始干预模型内部的认知流程。
在稀疏奖励下,
智能体如何高效探索
传统的大规模模型依赖逐词生成的方式进行探索。然而,对于那些需要多个正确步骤才能获得奖励的任务来说,由于奖励稀疏,导致智能体难以完成层次化的长序列任务。
这就像一个人蒙着眼睛在迷宫中行走,直到到达终点才会得到反馈,并且期间没有任何指引,无论尝试多少次都无法找到出口。
当下的大模型智能体通常需要外挂规划器才能处理复杂的、多步骤的任务。而谷歌的研究则是让智能体通过特定顺序访问一系列彩色位置(子目标),只有在完全正确的序列完成后才会得到奖励。
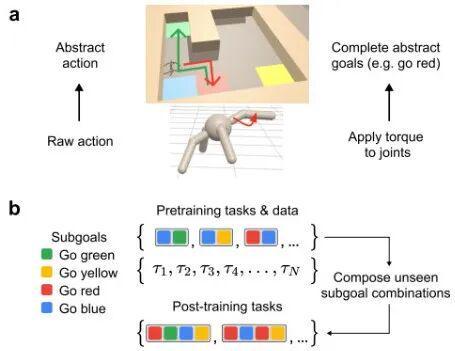
图1:智能体需按顺序穿过不同颜色的方块
这类“组合式任务”要求智能体掌握层次化解决问题的能力,不仅需要基础的动作控制技能,还需具备高级的时间规划能力。
它类似于人类执行搬运水杯的任务时所采取的一系列连贯动作:“拿起杯子→走到桌前→放下杯子”。
「大脑中的大脑」
AI自我发现抽象动作
那谷歌团队是如何应对稀疏奖励带来的挑战的?
解决方案是元控制器(Metacontroller)。
元控制器通过接收基本模型产生的残差流,可以生成一系列简单的内部控制模块。
每个内部控制对应一个时间抽象动作,并附带终止条件。结合多个控制模块,智能体可以在新任务中实现高效的探索。
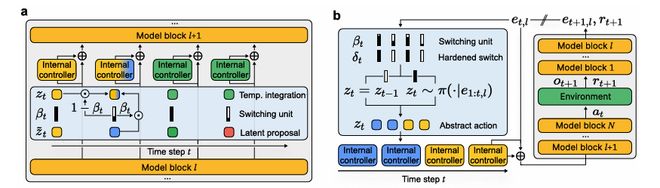
图2:元控制器引导预训练自回归模型的残差流激活
利用自监督学习预测下一步的动作,元控制器发现如何生成一系列稀疏变化的时间抽象动作序列。
在分层结构的任务中,每个内部控制对应一个时间抽象动作,指导基础自回归模型实现有意义的目标。
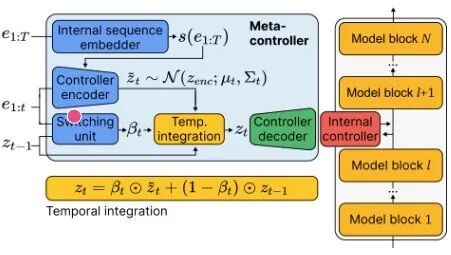
图3:元控制器的架构
通过强化学习,研究者观察到元控制器能够自动识别有意义的行为模块,这相当于无监督地发现如何执行抽象动作。
使用元控制器训练机器人泡茶时,不需要人工编码任务的多个步骤。
元控制器还能动态控制时间整合,它可以通过开关单元来调节每一步动作的时间长度。此外,它可以组合泛化,将学到的抽象动作应用于解决新任务。
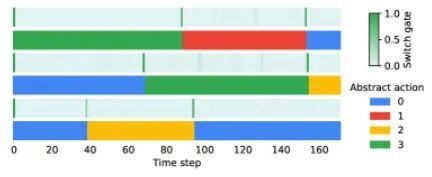
图4:自监督元控制器在预训练的自回归模型中发现时序抽象动作
元控制器学习到的切换模式可以与真实子目标切换完美匹配,尽管它从未接收过子目标标签。这种根据环境调整使用何种子目标的方式是自然产生的,表明模型内部形成了类似“选项”的层次化结构。
内部强化学习
新颖高效的训练方式
该研究最引人注目的地方在于,通过元控制器进行的内部强化学习与传统在原始动作空间上微调的方式不同。它在一个发现的抽象动作空间中进行学习,从而显著减小了搜索空间。在需要组合泛化的任务中,这种方式的成功率远超所有基线方法,包括最先进的分层强化学习方法CompILE。
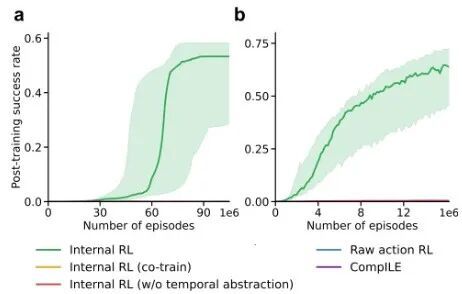
图5:各种强化学习方式的成功率
智能体之所以能够以更高的概率学会完成复杂的多步骤任务,是因为有了元控制器后,模型隐含地学会了将长序列任务分解为可重用的子程序(例如“移动到某个颜色区域”),从而缩小了搜索空间,并减少了奖励稀疏性。
这相当于通过降低动作空间维度,将高维残差流压缩成低维抽象空间。再加上在抽象时间尺度上操作,缩短有效的时间跨度。这使得奖励分配更加高效。
“觉醒-睡眠”训练循环的具体实施
早在2015年,Jürgen Schmidhuber提出了一种“觉醒-睡眠”训练循环的理论框架。
其核心思想是构建一个自我改进的迭代过程,在两个阶段之间交替执行,以创建能够形成和利用时间抽象与规划能力的自主智能系统。
在“睡眠”阶段中,智能体会回顾其过去的行为(观察和行动序列),通过自监督学习训练出一个内部世界模型。
“觉醒”阶段则使用在“睡眠”阶段学到的世界模型进行强化学习和规划以发现新的、有价值的行为。获得的新经验会被加入到经验库中,用于下一轮的“睡眠”阶段来改进世界模型。
谷歌的研究可以被视为“觉醒-睡眠”训练循环的具体实现,自回归基础模型预训练对应于“睡眠”阶段,在大量未标注的数据上进行训练以预测下一个标记(这里是动作或观察)。
这一过程正是自监督学习,使模型能够推断智能体的潜在目标(如子目标),并在其残差流激活中形成时间抽象表示。
“觉醒”阶段则是元控制器及其驱动的内部强化学习。它学会如何操控基础模型的内部残差流激活以生成有意义且持续多个时间步的动作,例如“前往蓝色位置”。
这相当于在世界模型的内部状态空间中进行规划和控制。
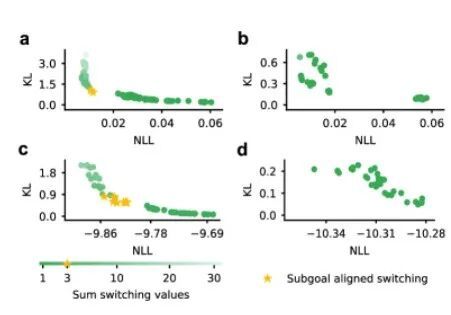
图6:预训练自回归模型被冻结的重要性
当基础自回归模型在元控制器训练期间被冻结时(如图6所示),才会涌现出与子目标对齐的正确切换表示,支持这一发现。
这一结果强烈证明了“觉醒-睡眠”循环分阶段迭代思想的有效性:首先通过预训练建立高质量、稳定的世界模型(基础模型);然后在此基础上学习控制策略。如果两者同时训练,则会收敛到一个劣质解决方案而无法发现有意义的时间抽象。
这符合Jürgen Schmidhuber提出的“先睡眠后觉醒”的循环训练方案,强调构建模型后再进行控制学习的重要性。
一直以来,关于自回归模型的批评认为无论参数量多大,都只是“随机鹦鹉”,难以形成一致的时间抽象和规划能力。然而这项研究表明,结合元控制器能够诱导出层次化的时间抽象,与人类解决问题的方式高度相似。
不依赖手动奖励塑造就能解决需要多步骤才能完成的任务,是向能够导航复杂开放搜索空间的自主智能体迈进的关键一步,在这些环境中中间进度往往难以定义。
终结随机鹦鹉争论
谷歌团队的研究标志着AI研究从单纯优化模型输出转向理解和操控内部认知过程,为开发具有真正层次化推理能力的通用人工智能系统提供了坚实的实践基础。这证明模仿人类睡眠有助于实现复杂时间序列任务的学习效率提升。
与稀疏自编码器等解释性方法相比,元控制器明显占优:直接通过残差流干预减少预测误差;具备内部记忆支持长时间跨度的干预;并能发现可解释且长期持续有效的策略。
这项技术的应用前景非常广泛。
在机器人控制领域中,可以让机器人执行需要多步骤协调的任务;对于数学推理而言,则可以自主将复杂问题分解为简单的推理步骤;在科学探索方面也能使智能体在稀疏奖励环境中进行高效探索和假设检验。
谷歌提出的内部强化学习方法特别适用于长期规划及组合推理场景,为实现真正通用的智能系统开辟了新路径。
这项技术的潜在应用极其广泛。
在机器人控制中,可让机器人执行需要多步协调的复杂任务;对于数学推理,能自主将复杂问题分解为可管理的推理步骤;对于科学发现,也可让智能体在稀疏奖励环境中进行高效探索和假设检验。
谷歌提出的内部强化学习范式,尤其适合需要长期规划和组合推理的场景,为实现真正通用的智能系统提供了新路径。
参考资料:
https://arxiv.org/abs/2512.20605