DeepSeek团队最近在ArXiv上低调发布了一篇论文,介绍了一个新的智能体推理框架DualPath。
该研究针对Agent长文本推理场景中的I/O瓶颈问题,提出了解决方案:通过优化KV-Cache的加载速度来减少计算资源被存储读取拖累的情况。
DualPath打破了传统的从外部存储直接加载到预填充引擎(Storage-to-Prefill)模式,引入了第二条路径——从外部存储加载至解码引擎再传输给预填充引擎。

这种双路径策略利用了解码引擎闲置的SNIC带宽,并通过RDMA技术将缓存高速传输至预填充引擎,实现了集群存储带宽的全局池化与动态负载均衡。
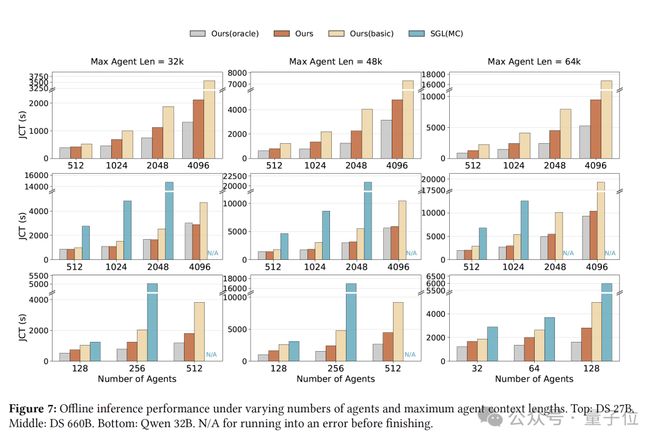
实验结果表明,在660B规模的模型上,DualPath显著提高了离线推理和在线服务的吞吐量:前者提升了1.87倍,后者平均提升1.96倍。同时,首字延迟(TTFT)得到了大幅优化,而Token间的生成速度几乎没有受到干扰。
接下来我们深入了解一下这个框架的设计理念和技术细节。
双路径加载机制
DualPath的核心观点是KV-Cache的加载不需要围绕预填充引擎进行。传统做法通常是由负责计算的部分去搬运数据,而DualPath则让缓存先被加载到解码引擎中,再通过高速网络传输至预填充引擎。
这种方法能够动态分配网络负载,减轻了预填充侧的带宽压力,并利用了解码侧闲置资源,实现了全局带宽的最大化利用。
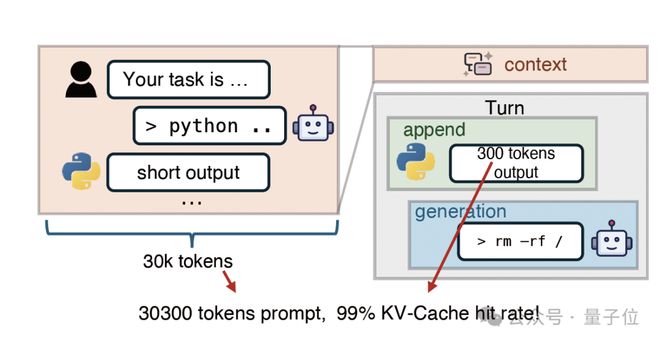
为什么需要绕路呢?
在当前智能体应用中,对话轮数多且上下文长,KV-Cache命中率极高。这意味着每一轮对话都需要搬运大量的“旧记忆”,推理性能的瓶颈已经从计算转向了数据搬运。
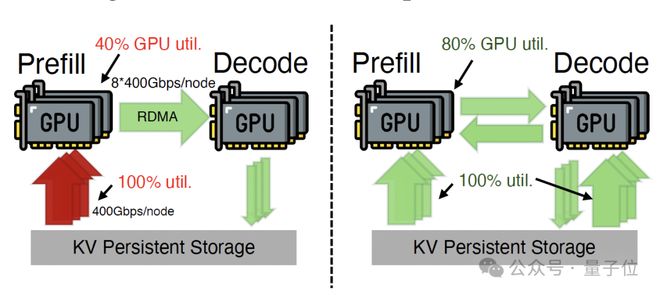
而在现有的架构中,所有加载任务都集中于预填充引擎(PE)的存储网卡上,导致带宽饱和;与此同时,解码引擎(DE)的存储网卡却处于闲置状态,造成资源错配问题加剧。
此外,GPU算力的增长速度远超网络带宽和HBM容量增长的速度,进一步放大了I/O瓶颈。
为此,DualPath设计了一个创新性的双路径模型:
路径A(传统):存储直接加载至预填充引擎。
路径B(新增):存储先加载至解码引擎的缓冲池中,再通过RDMA传输给预填充引擎。
框架由推理引擎、流量管理器和中央调度器组成。每个推理引擎负责一块GPU,并明确区分了预填充(PE)与解码(DE)。流量管理器处理各种数据传输任务,而中央调度器根据实时情况决定每条请求的最佳路径。
核心技术方案:存储至解码
DualPath的核心在于打破了传统的单路径模式,引入了“存储至解码”路径。这意味着KV-Cache先加载到解码引擎(DE),再通过高带宽计算网络传输给预填充引擎。
为了支持层级流式处理,DualPath在PE和DE上分配了少量的DRAM缓冲区,并针对不同阶段设计了精细的数据流动方案:PE读取路径、DE读取路径以及解码与持久化过程。
在实验中,DualPath还在DeepSeek-V3等模型上进行了测试,涵盖了离线Rollout和在线服务场景。结果显示,离线推理的端到端吞吐量提高了高达1.87倍,在线服务吞吐量平均提升1.96倍,且首字延迟(TTFT)显著降低。
总之,DualPath通过重新设计数据加载路径证明了可以有效突破当前大模型推理中的I/O瓶颈问题。它充分利用了解码引擎闲置的带宽资源,并结合自适应调度和流量隔离机制,在不增加硬件成本的前提下提升了智能体LLM系统的效率。
此外,这篇论文的第一作者吴永彤是北京大学的一名博士生,专注于系统软件与大模型基础设施的研究工作。他目前在DeepSeek团队中参与下一代模型推理基础设施的建设,负责大规模软件系统在多平台上的性能优化任务。
针对这些问题,DualPath构建了创新的双路径模型:
- 路径 A(传统):存储→PE,缓存直接读入预填充引擎。
- 路径 B(新增):存储→DE→PE,缓存先读入解码引擎的缓冲池,再通过RDMA传输给预填充引擎。
在架构组成上:
- 推理引擎: 每个引擎管理一块GPU,严格区分为预填充(PE)和解码(DE)。
- 流量管理器: 负责H2D/D2H拷贝、引擎间传输以及SNIC存储读写。
- 中央调度器: 担任“大脑”角色,实时决策每一条请求该走哪条路,从而实现全局带宽的最大化利用。
核心技术方案:存储至解码路径
如上所述,DualPath推理系统的核心在于打破了传统的“存储至预填充”单路径模式,创新性地引入了“存储至解码”路径
该设计允许KV-Cache先加载至解码引擎(DE),再通过高带宽计算网络(RDMA)无损传输给预填充引擎(PE)。
通过在两条路径间动态分配负载,系统将集群中原本闲置的解码侧存储网卡(SNIC)带宽彻底释放,构建起一个全局可调度的存储I/O资源池。
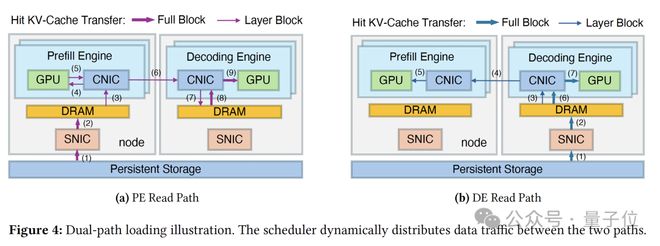
具体来说,为了支持层级流式处理,DualPath在PE和DE上均分配了少量DRAM缓冲区(PE/DE Buffer),并针对不同阶段设计了精细的数据流:
- PE读取路径: 命中Token的KV-Cache从存储读入PE缓冲区。在每层计算前,该层缓存传输至PE HBM,与计算过程重叠执行。计算完成后,全量KV-Cache传回DE缓冲区以形成完整上下文。
- DE读取路径: KV-Cache直接进入DE缓冲区。在PE预填充期间,对应层的缓存跨节点传输至PE HBM(计算重叠)。计算结束后,PE仅需传回新生成的KV-Cache片段与DE原有缓存合并。
- 解码与持久化: DE缓冲区接收完整KV-Cache后启动解码,执行H2D拷贝并随后释放CPU内存。虽然引入缓冲增加了DRAM压力,但能显著降低GPU显存占用并优化首字延迟(TTFT)。生成过程中,每累积满一个Block(如 64 Token)即触发异步持久化。
但就像前面提到的,“绕路”加载会带来新问题:比如搬运缓存的流量撞上了模型计算的通信,怎么办?
对此,DualPath给出了两套优化方案:
首先是以计算网卡(CNIC)为中心的流量管理,强制所有流量通过配对的CNIC走GPUDirect RDMA路径。
在InfiniBand或RoCE网络中,利用虚拟层(VL/TC)技术,将推理通信设为“最高优先级”并预留99%带宽,让缓存搬运只能在间隙中“蹭”带宽,确保互不干扰。
其次是自适应请求调度器: 调度器会盯着每个节点的磁盘队列长度和Token数。系统会优先将任务分配给I/O压力较小且计算负载较轻的节点,从根本上避免单侧网卡或单点计算资源的拥塞。
在实验阶段,DualPath在DeepSeek-V3、Qwen等模型上进行了测试,场景覆盖了离线Rollout和在线服务。
如开头所说,在离线推理中,DualPath 将端到端吞吐量提高了高达1.87倍,在线服务吞吐量平均提升1.96倍,显著降低了首字延迟(TTFT),且保持了极其稳定的Token间延迟(TBT)。
总的来说,DualPath 证明了通过重新思考数据加载路径可以有效突破当前大模型推理的I/O墙。
它成功利用了解码引擎原本被浪费的I/O带宽,配合自适应调度和严谨的流量隔离机制,在不增加硬件成本的前提下,大幅提升了智能体LLM推理系统的效率。
One more thing
这篇论文的第一作者吴永彤,是北京大学的博士生,师从金鑫教授。
他的研究方向聚焦于系统软件与大模型基础设施(LLM Infrastructure),尤其是推理系统的工程优化与规模化部署。

他目前在DeepSeek系统组,参与下一代模型的推理基础设施建设,负责大规模软件系统在多硬件平台上的性能优化。

此前,他还曾在腾讯、华盛顿大学,微软亚研院等机构实习。
[1]https://arxiv.org/pdf/2602.21548
[2]https://jokerwyt.github.io/