
近年来,基于大语言模型的多智能体系统(MAS)在复杂推理任务中得到了广泛应用。传统方法通常让多个独立生成决策的代理通过投票或辩论等方式进行聚合,从而提高算术、常识推断及专业问答等领域的准确率。
当test-time compute成为常见的性能提升策略时,一个自然而然的问题随之产生:随着agent数量的增加,MAS是否能够持续增强其能力?直观上来看,这种想法似乎是合理的:类似ensemble或self-consistency的方法通过多次采样和聚合通常可以提高覆盖正确答案的概率。
上海交通大学、加州大学伯克利分校、加州理工学院以及约翰・霍普金斯大学的研究团队联合发表了一篇名为《Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity》的论文,该研究揭示了多智能体系统「扩不动」的真实原因,并非是代理数量不足,而是信息冗余。实验结果显示,单纯增加系统的规模并不会带来持续性的性能提升;相比之下,引入多样性能够显著延迟饱和点的到来,并在使用较少agent的情况下实现更强的表现。

- 论文标题:《Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity》
- 该研究通过一系列实验展示了规模扩展和多样性的不同影响。首先,在同质设置下,所有代理共享相同的底座模型与系统提示,并采用两种常见的协作机制进行评估:
- 投票:单轮独立生成后多数投票;
同质扩展的失效:
辩论:多轮交互后再给出最终答案(四轮交互)。
实验仅改变agent数量,在七个基准任务上进行了测试,包括GSM8K、ARC、形式逻辑、TruthfulQA、HellaSwag、WinoGrande和Pro Medicine。结果表明,当代理数量从1增加到2或4时,性能通常会有明显提升;但继续增加代理数量后,准确率很快进入平台期,边际收益接近于零,在某些设置下甚至出现下降趋势。
- 多样性配置带来了不同的实验现象:
- 少量异质agent的表现优于大规模同质系统。
在多样性的条件下,研究进一步对比了两类系统的性能:一类由同一模型多次独立运行构成,另一类则由不同基础模型或具有不同角色提示的代理组成。在相同的计算预算下,前者通常表现更佳,并且在更大的agent数量设置中仍能保持增益。

为了深入理解这一现象,作者将多样性分解为不同的来源,包括角色多样性和模型多样性,并进行了系统对比实验。
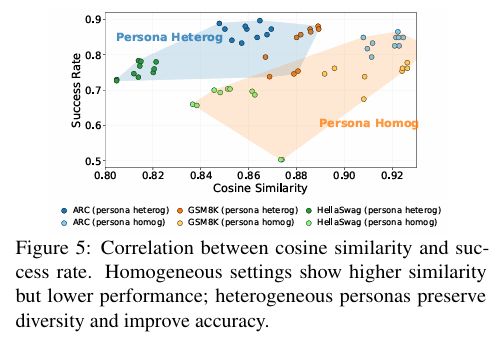
在GSM8K、ARC、HellaSwag和TruthfulQA等任务上进行的比较显示:每引入一层新的多样性特征,系统的整体性能都会有显著提升;其中,模型多样性和角色多样化各自都具有独立贡献,而两者结合时效果最佳。
这种趋势在效率方面尤为明显:使用两个完全异质的代理就足以达到甚至超过使用16个同质代理的平均表现水平。
多智能体扩展瓶颈不在于规模
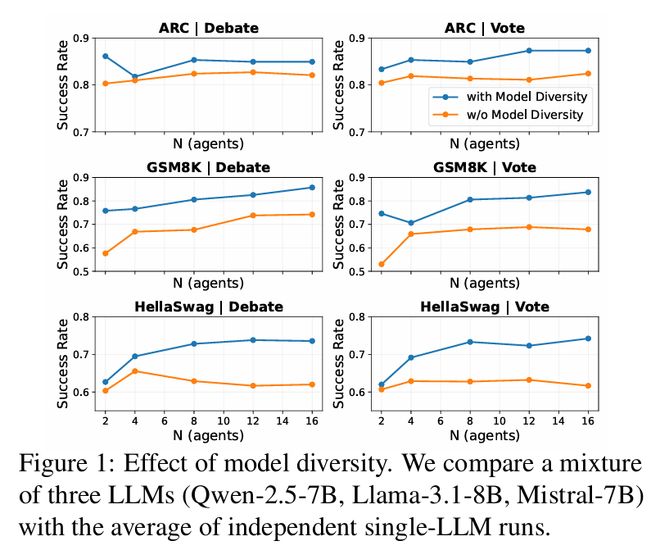
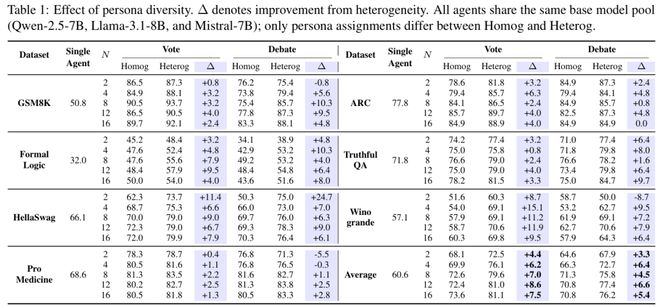
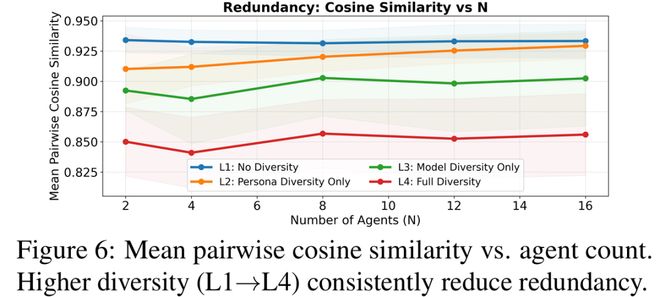
将上述实验结果整合起来,论文得出一个明确结论:多智能体系统的扩展限制并非来自于agent数量不足,而是由于这些agent之间的高度相关性。在同质配置下,新增加的代理往往沿着相似路径生成答案,重复采样带来的边际效益有限;而多样性则有助于引入互补视角,减少输出冗余,使系统能在相同甚至更小计算预算下获得更多的有效信息。
基于这些观察结果,作者提出了基于信息论分析框架来解释「规模失效」与「多样性优势」。这项工作强调了多智能体系统中真正稀缺的资源并非调用次数,而是非冗余的信息来源。
- 性能由有效信息而非调用次数主导
- 该研究探讨了一个包含N个大模型代理的多智能体系统,每个代理具有自身的配置,包括基座模型、系统提示词、角色设定和工具能力。系统接收问题输入X,并按预设流程执行多次推理,最终输出答案Y。
- 从信息论的角度来看,得到正确答案的成功率并不由N或n决定,而是取决于系统提供的有效信息量。条件熵H(Y|X)被用来描述任务的难度:在给定问题X的情况下,正确答案Y仍存在的不确定性。
- 同质配置下,即便新增加代理也只是重复采样相同的推理路径;而在异质配置中,新增加的代理更可能引入新的推理路径与现有路径互补,从而更有效地减少不确定性。
为刻画这一差异,作者定义了系统可获得的有效信息量,并据此关联成功率。研究发现:影响系统性能的关键在于有效信息通道的数量——即多样化所带来的非冗余信息规模。
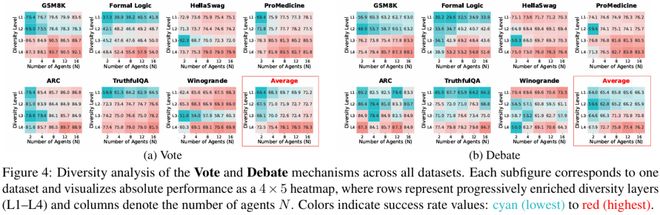
进一步地,该研究提出了一种估计有效信息通道K的方法,并在多个数据集上进行了验证。
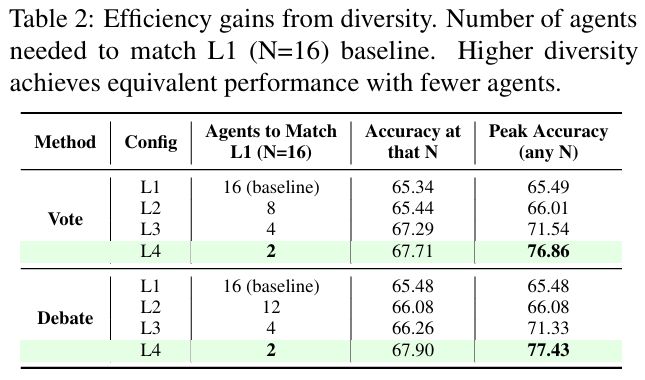
实验结果表明:当正确推理路径对应的有效信息通道更多时,多智能体系统表现更好。这提示我们在设计系统时不应追求多样性本身,而是与任务相关的推理多样化——即提升与正确推理相关的信息量。
而是信息冗余
论文的核心结论是:扩展的关键不在于增加N的规模,而是在于让新增调用带来新的有效证据;只有当输出高度相关时,同质扩展才会迅速进入平台期;而多样性能够提高效率是因为它更可能产生互补推理路径。换句话说,在多智能体系统中真正稀缺的是非冗余信息。
实践上可以通过一个简单的标准来指导扩展:当增加代理主要带来同一思路的重复时,应停止堆砌同质数量,并引入可控异质性(如使用不同模型家族、角色提示或工具能力互补);只有在这些改动确实带来更多增益的情况下,再继续扩大规模。
信息论视角:
性能由「有效信息」而非「调用次数」主导
作者考虑一个包含 N 个大模型智能体的多智能体系统,每个智能体具有自身配置,包括基座模型(backbone model)、系统提示词(system prompt)、角色设定(persona)与工具能力(tool access)。系统接收问题输入 X,按预设工作流执行若干次推理(记为 n 次),最终输出答案。
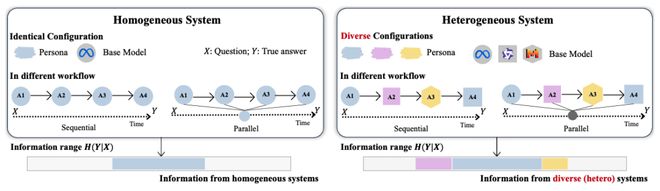
从信息论角度,得到正确答案 Y 的成功率并不简单由 N 与 n 决定,而取决于系统能够提供多少关于 Y 的信息。作者用条件熵 H (Y|X) 刻画任务的内在难度:在给定问题 X 的情况下,正确答案 Y 仍然存在的剩余不确定性。
- 同质配置下,即便新增智能体,往往也只是在相似推理路径下重复采样,因而对降低不确定性帮助有限;
- 异质配置下,新增智能体更可能引入新的推理路径,与既有路径互补,从而更有效地减少不确定性。
为刻画这一差异,作者定义:

在该设定下,作者基于若干建模假设推导出一个近似形式,用于刻画趋势而非精确预测。作者认为,系统可获得的有效信息量(并据此关联成功率)主要受如下量支配:

该结果强调:影响系统性能的关键不在于 “智能体数量或推理次数”,而在于系统中有效信息通道的数量—— 也就是多样化所带来的非冗余信息规模。它也解释了为何实践中常见「边际效益递减」:当有效信息通道增长受限时,新增调用带来的有效信息增量会快速衰减。
作者还给出了在实践中估计有效信息通道 K 的方法,并在 GSM8K、ARC、Formal Logic、HellaSwag、WinoGrande、Pro Medicine 等数据集上验证:经验成功率与理论预测总体吻合。
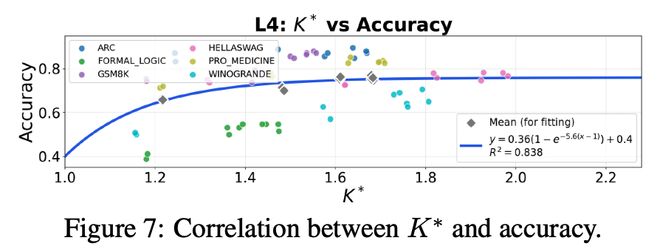
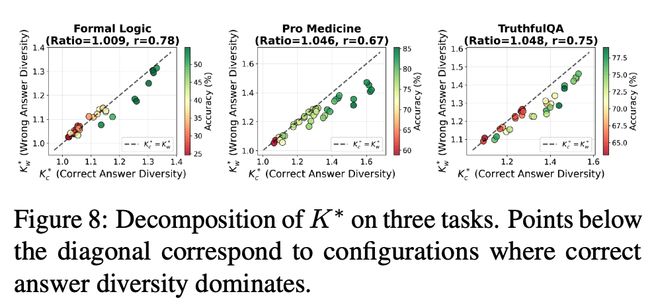
进一步地,作者将系统输出拆分为「正确推理路径」与「错误推理路径」,分别估算其对应的有效信息通道数量。实验一致表明:当正确推理路径对应的有效信息通道更多时,多智能体系统表现更好。这意味着系统设计不应盲目追求多样性本身,而应追求与任务相关的推理多样性 —— 即提升与正确推理相关的有效信息通道数。
总结
论文的核心经验结论是:多智能体扩展的关键不在于把 N 做大,而在于让新增调用带来新的有效证据。只要输出高度相关,同质扩展就会很快进入平台期;而多样性能够提升效率,是因为它更可能产生互补推理路径。换句话说,多智能体系统里稀缺的不是调用次数,而是非冗余信息。
实践上可以用一个简单标准指导扩展:当增加 agent 主要带来「同一思路的重复」 时,应停止堆同质数量,转而引入可控的异质性(方法互补的 persona、不同模型家族、工具能力互补);只有当这些改动确实带来额外增益时,再继续扩大规模。