全球首个深度思考的扩散模型诞生!
它摒弃了传统的自回归模式,成为世界上生成速度最快的模型。
对比之下,传统自回归的“打字机式”输出方式(逐个token按顺序生成)就像乌龟一样慢:

实际测试结果显示,在英伟达GPU上运行的Mercury 2扩散推理大语言模型可实现每秒1009个tokens的速度。
这一速度比GPT-5(mini版)和Claude-4.5(haiku版本)等传统模型快了五倍之多。

消息传出后,英伟达迅速表达了祝贺之情(或许是因为它投资了Mercury 2背后的公司):
网友们也纷纷热议,毕竟最近火热的“龙虾们”对速度有着极致追求:
有人开始怀念自回归模型曾经的地位(doge表情)。
那么问题来了,Mercury 2究竟是谁?又是如何突破了速度瓶颈呢?
原理其实很简单。
传统自回归方法就像打字机一样,一次只能处理一个token,并且必须按顺序从左到右进行操作。
而扩散模型Mercury 2的工作方式更像是编辑——
不是看它在逐个输入字符,而是看到它拿到一份草稿后立刻进行全面修改。
换句话说,在生成完整答案的草案后再进行整体优化。
这种“并行处理”机制让Mercury 2无需等待前一个字的结果就能生成下一个字,因此响应速度极快,并且延迟不再与输出长度成正比关系。
因此,它的生成速度大幅提升至五倍以上,其速度曲线也与众不同。
在第三方测试中,它以明显优势领先于其他模型。
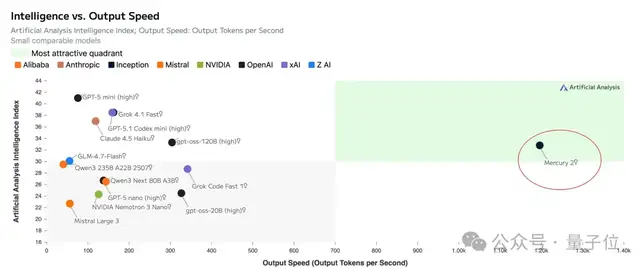
与其他主流顶级模型相比,在速度上更是独具一格。
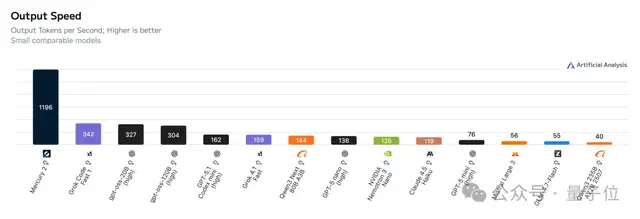
更重要的是,除了速度快以外,Mercury 2在性能和价格方面也有显著优势。
它的延迟低至1.7秒,并且在GPQA(科学问答)、LCB(编程)及AIME(数学)等基准测试中表现优异,得分普遍高于或持平于那些速度较慢的小型/轻量级模型如GPT-5 Nano和Claude 4.5 Haiku。
在AIME上甚至超过了公认的“性能怪兽”Gemini 3 Flash(推理版)。
这表明Mercury 2在保持极高生成速度的同时,没有牺牲智能水平。
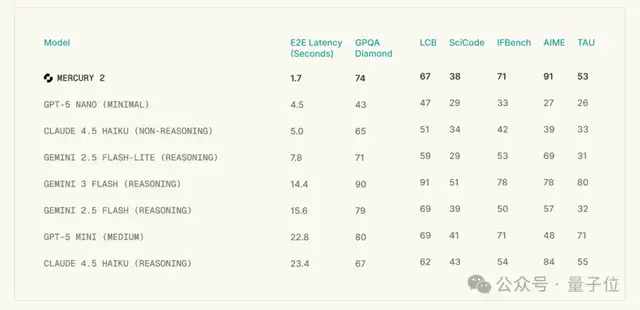
目前它支持128K的上下文,并且输入价格为每百万token0.25美元(约合人民币1.7元),输出价格则是每百万token0.75美元(约合人民币5.2元)。
从性价比角度来看,Mercury 2仍然处于较高水平。
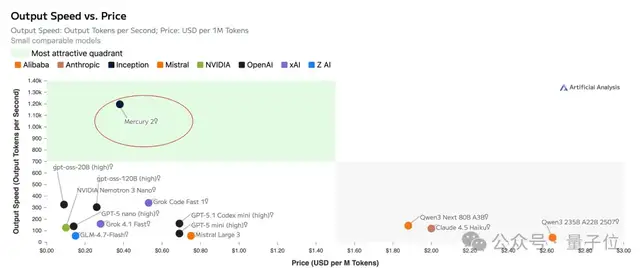
官方表示,这种速度优势彻底改变了推理过程。
接下来介绍一下Mercury 2背后的公司和团队信息。
这个模型是由成立于2024年的硅谷初创企业Inception Labs推出的。
自成立之初,这家公司就专注于扩散模型的研发,其核心目标是——
替代传统的自回归Transformer架构,通过全新的、基于扩散的生成机制从根本上解决速度和成本问题。
他们认为传统自回归模式存在明显的缺陷:延迟时间和成本会随着token数量增加而递增。
而扩散模型采用由粗到细的方法进行生成。它不是逐个提交数据,而是通过少量步骤并行迭代地细化输出结果。这使得在生成过程中可以修改内容,并带来截然不同的速度-成本曲线。简而言之:
人工智能不应该像单向打字机那样工作,而应该更像一个编辑。
基于这种理念,Mercury系列开始在实践中得到应用和发展。
2025年2月,全球首个基于扩散模型的商业级语言模型——初代Mercury发布,其生成速度达到了传统自回归模式的五倍以上。同时推出的还有编程助手Mercury Coder。
在一年后的今天,升级版Mercury 2面世,在推理和多智能体技术日益流行的背景下带来了更多的可能性。

实际上早在2019年,该公司的联创兼CEO Stefano Ermon就开始研究扩散模型了。
当时Stefano Ermon是斯坦福大学计算机科学教授,他很早就考虑将扩散模型应用于内容生成领域。
此前的主流图像生成技术大多使用GAN(生成对抗网络),但他和他的团队认为这种方法“不够好”,于是开始尝试应用Diffusion方法。
在看到Diffusion的良好效果后(后来Midjourney和DALL-E等产品都是采用这一方法),他们将研究重心转向了文本和代码的生成领域。
图像由连续像素组成,而文本则是离散token构成。之前成功的扩散模型理论(如去噪得分匹配)是在连续空间上建立起来的,无法直接应用于文本生成。
于是,在2023年,他们发表了一篇关键性论文《Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution》,介绍了一种名为Score Entropy Discrete Diffusion models(SEDD)的新方法。
这一模型创新地提出了“分数熵”这一损失函数概念,巧妙地将连续空间的理论扩展到了离散数据领域。
这使得扩散模型能够像理解图像那样去理解和生成语言。

论文结果表明,SEDD的表现明显优于当时已有的语言模型,在困惑度上比未退火的GPT-2高出6-8倍。
(注:此论文后来获得了ICML 2024最佳论文奖)
看到这一成果后,Stefano Ermon决定创办公司来放大这项技术的价值。
因此,在2024年夏天,他邀请了美国加利福尼亚大学洛杉矶分校的教授Aditya Grover和康奈尔大学的教授Volodymyr Kuleshov加入Inception Labs。

去年11月,这家公司宣布获得了5000万美元的投资,并且投资阵容十分豪华。
其中包括NVentures(英伟达风投部门)、M12(微软旗下风险基金)和Menlo Ventures (领投方、知名长期风投机构),以及AI领域的重量级人物吴恩达和卡帕西等人的支持。
坚持走扩散模型路线的Inception Labs始终稳扎稳打,并获得了市场的认可和支持。
最后顺便提一下,Mercury 2目前暂无开源计划,但其API兼容OpenAI标准。
对这款产品感兴趣的朋友们可以亲自体验一番。
体验地址:
https://chat.inceptionlabs.ai/