
想象一下,如果你让一个AI助手利用搜索工具来解决复杂问题时,它可能第一次探索就走错了方向,并且在后续尝试中重复相同的错误路径。虽然你可以从多次探索的结果中选出一个还算满意的答案,但这种方法不仅低效,还需要人工干预。这种现象是大多数深度搜索智能体面临的挑战之一——它们无法「记住」之前的探索经历,在每次新的任务开始时都得重新开始,导致大量的冗余搜索和资源浪费。
当前的许多深度搜索模型多采用ReAct框架构建,并以线性推理方式运作:「思考→调用工具→观察→再思考」。这种方式在处理简单问题上表现良好,但在需要多次迭代探索的任务中则显得力不从心,容易陷入局部最优、重复探索和低效搜索的困境。
为了应对这一挑战,东南大学和微软亚洲研究院的研究团队提出了一种名为Re-TRAC(REcursive TRAjectory Compression)的新方法。这种方法使AI智能体能够「记住」每一次探索的经验,并在不同尝试之间传递这些经验,从而实现渐进式的搜索方式。

- 论文标题:RE-TRAC: REcursive TRAjectory Compression for Deep Search Agents
- 论文链接:
- 通过将探索过程转变为一个持续学习的过程,该方法旨在克服ReAct框架的局限性。具体来说,在每个探索阶段结束时生成一个结构化的状态表示,记录关键信息以供后续使用。
- 项目链接:
- 现有深度搜索模型即使经过大量强化学习训练后,其Pass@K性能仍然远高于Pass@1,这表明模型具有解决问题的能力,但受限于上下文长度,单次探索难以覆盖足够宽广的搜索空间。
Re-TRAC的核心思想在于将独立探索尝试转变为渐进式学习过程。在每次探索结束后生成结构化状态表示,并记录以下三个方面信息:
答案与分析结论:提供当前最可能的答案及其关键推理结果,为后续推理提供参考;
证据库与来源验证:列出已搜集的证据和其来源,并标记哪些已被查阅、被验证过——避免重复工作;
不确定项与待探索方向:指出需要继续调查的问题领域或未解决的方向。
这种方法确保智能体在每次新的尝试开始时都能够清楚地了解什么已经被确认,什么是未知的,并据此制定下一步行动计划。
小模型也能实现高效搜索
- 研究人员评估了Re-TRAC在五个具有挑战性的基准测试中的表现:BrowseComp、BrowseComp-ZH、XBench、GAIA和HLE。
- RE-TRAC-4B在所有小于15B参数的模型中表现出色:
- 在BrowseComp上准确率达到30.0%;
BrowseComp-ZH上的准确率为36.1%;
GAIA上的准确性为70.4%;
XBench上的得分高达76.6%;
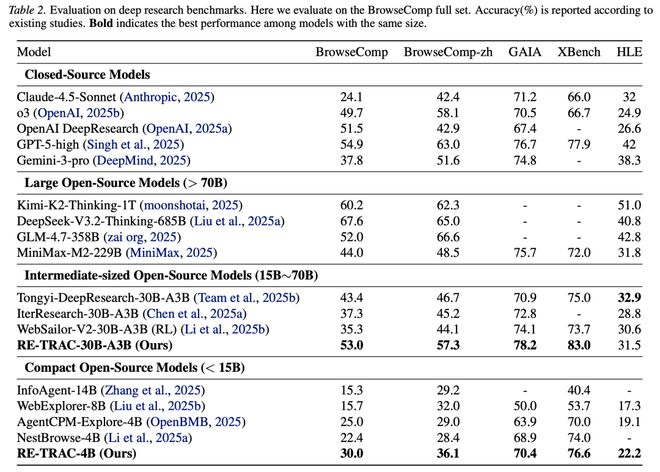
HLE上的得分为22.2%。
更令人惊讶的是,一个仅拥有4B参数的小模型,在多个基准上超越了更大规模的竞争对手。
- 例如,在XBench测试中,RE-TRAC-4B达到76.6%,比InfoAgent-14B(准确率为40.4%)高出近90%,同时优于NestBrowse-4B(得分74.0%)。
- 在GAIA基准上,RE-TRAC-4B的准确性为70.4%,超过了AgentCPM-Explore-4B (63.9%) 和 NestBrowse-4B (68.9%) 的表现。
- 30B参数模型的表现
- RE-TRAC-30B同样显示出卓越性能,在除HLE以外的所有基准上均胜过MiniMAX-M2-229B:
- 在BrowseComp上的准确率达到53%,超过GLM-4.7-358B的52%。
GAIA测试中,RE-TRAC-30B超越了所有闭源模型,在BrowseComp和BrowseComp-ZH上排名第二。
- 结果表明,通过轨迹压缩及跨轮次信息传递机制,小模型在资源受限场景下也能实现接近甚至超过大型模型的效果。
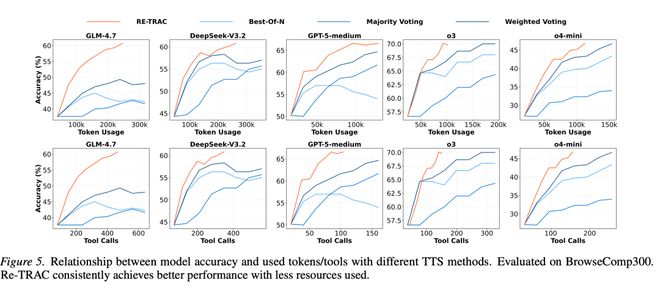
- 更低的消耗、更高的性能
Re-TRAC不仅可以提高小型模型的表现,还可以作为无需额外训练的方法直接应用于前沿模型中。研究团队已在o4-mini、o3、GPT-5、DeepSeek-V3.2等多款模型上实现了该框架。
实验数据表明,在BrowseComp子集中:
- o4-mini的准确率通过Re-TRAC提升至46.8%(从25.7%);
- o3提升了15%,达到69.8%;
GPT-5-medium则从48.3%升至66.6%;
DeepSeek-V3.2从45.3%提升到60.8%;
GLM-4.7的准确率也由原来的37.7%提高到了60.7%。
传统框架中由于每次探索都相互独立,随着模型规模的增长,资源使用量呈线性增加。而Re-TRAC继承了先前轮次的状态信息,使得搜索空间逐步收敛,并减少重复任务执行频率,从而提高了整体效率。
如何训练Re-TRAC模型
- 该团队开发了一种后训练方法,在构建基于结构化状态表示的监督微调(SFT)数据集过程中使用实体树技术收集大量实体作为树根,递归搜索相关实体直至达到预定义深度。
- 然后选择从根节点到叶子节点的路径并将边转换为子问题以合成问答对。利用GLM-4.7在这些合成问题上的Re-TRAC轨迹过滤后得到104k个训练样本,用于模型训练。
- 实验显示Qwen3-4B-Instruct在BrowseComp上的准确率从2.7%大幅跃升至30.0%,而在BrowseComp-ZH上则由6.9%提升到36.1%,GAIA和XBench上的得分也分别达到了70.4%与76.6%。
- 这些结果证明通过简单的SFT训练配合Re-TRAC框架,能够显著增强搜索智能体的性能,并且可能超过那些经过大规模强化学习训练的模型。
- 优化深度搜索任务中的探索机制
Re-TRAC可以视为针对深度搜索任务优化过的ReAct框架:在原有的“思考-调用工具-观察-再思考”模式上引入了跨轮次轨迹压缩和结构化状态表示,使得智能体不再需要每次都从零开始,在复杂的网络检索与信息汇总场景中能够重复使用已有证据、总结失败经验并规划未来的探索方向。
技术细节:
通过这种有针对性的设计,小型模型在资源受限环境中也能展现出接近甚至超越大型模型的表现,为边缘设备和本地部署提供了可能的解决方案。
研究团队开发了一种后训练方法,构建了基于结构化状态表示的监督微调(SFT)数据。训练数据通过实体树方法构建:从维基百科收集大量实体作为树根,然后递归搜索相关实体作为子节点,直到树达到预定义深度。
通过选择从根到叶节点的路径并将边转换为子问题,团队合成了 33K 个问答对。然后,收集 GLM-4.7 在这些合成问题上的 Re-TRAC(4 轮)轨迹,经过过滤后得到 104k 个训练样本,用于训练 RE-TRAC-4B 和 RE-TRAC-30B 模型。
实验结果显示,经过 SFT 训练后,Qwen3-4B-Instruct 在 BrowseComp 上的准确率从 2.7% 大幅提升到 30.0%,在 BrowseComp-ZH 上从 6.9% 提升到 36.1%,在 GAIA 上从 24.4% 提升到 70.4%,在 XBench 上从 45.0% 提升到 76.6%。
这表明通过简单的 SFT 训练,配合 Re-TRAC 框架,可以产生强大的搜索智能体,实现与通过大规模强化学习训练的模型相当甚至更好的性能。
总结:
优化 ReAct 的搜索框架,
让小模型跑出大模型表现
Re-TRAC 可以看作是针对深度搜索任务优化过的 ReAct 框架:在原有「思考→调用工具→观察→再思考」的范式上,引入了跨轮次的轨迹压缩和结构化状态表示,让智能体在开放网络检索、复杂信息汇总等场景中不再「从零开始」,而是像人一样复用既有证据、总结失败教训并规划未来方向。
更重要的是,这种有针对性的框架设计让小模型也能跑出大模型级别的效果,为资源受限场景(如边缘设备、本地部署)提供了一条「用小模型做大事」的现实路径。