
在许多大型模型及代理的训练过程中,常见的方式是仅依据结果来判断:如果最终答案正确,则给予奖励;反之则得零分。
对于简单的问答任务,这种方法尚可适用;但当涉及到需要多轮对话、搜索和编写代码等复杂过程的任务时,这种评价方式就显得过于简化了。
因此,在差之毫厘的情况下与一开始就走错方向的情况之间,仅凭结果评判无法区分其优劣;训练过程中也无法识别出哪些失败更为关键,人工细粒度的评分又难以应对开放环境和多模态任务的复杂性。
香港中文大学和美团在这项研究中直接面对了这一核心矛盾:
代理需要获得详细的反馈来指导其长期行为及工具使用情况;然而,目前大多数系统提供的只是最终是否正确的粗略奖励信息。

- 论文标题:Exploring Reasoning Reward Model for Agents
- 论文链接:https://arxiv.org/pdf/2601.22154
- 项目地址:https://github.com/kxfan2002/Reagent
为了解决上述问题,研究人员开发了一款能够理解推理并评估工具调用的评价器,用于给代理的操作过程打分,并附上点评意见。这些反馈随后被重新纳入训练流程中。
这也是Reagent框架的核心理念:使代理不仅仅关注结果,还要对其思考和使用工具的过程负责。
为代理的思想评分
此项研究的关键创新在于不再单纯依据最终答案的正确与否来评判,而是开始对整个思考过程进行详细打分。
研究团队创建了一套专门针对智能体设计的数据集:其中包含各种真实的代理轨迹,包括推理流畅但执行失败的情况、随机猜测却侥幸猜中的情况以及工具使用不当的例子。每一条轨迹都附上了详细的评分及评语,指出哪些部分是合理的思考路径,哪些部分偏离了正轨。
基于此数据集,他们训练了一个专门的“思想评价模型”——Agent-RRM。该模型不仅关注最终答案,还会对整个过程进行全面评估,并输出三个结果:内部分析、用户反馈以及一个整体评分。
举个简单的例子:
- 即使两个代理都得到了正确的答案,但一个逻辑混乱且工具使用不当,另一个从一开始就清晰地规划了步骤并合理利用信息,两者可能获得截然不同的分数。
- 另一条从一开始就分析清楚、什么时候该搜、什么时候该点进网页、怎么利用信息都说得明明白白,这种思路就可能拿到 0.9。
与老师批改试卷时不仅看最终选择题的答案,还会评估中间的解题过程类似,这一方法旨在教导代理如何正确思考和使用工具,而不仅仅是猜测答案。
教会 Agent「怎么想」「怎么用工具」,而不是教它「怎么猜对答案」。
统一文本批评及奖励信号:Reagent框架
在有了能够评价“思想”的Agent-RRM后,还需要考虑如何将这些反馈信息有效地传达给代理。这正是Reagent框架要解决的问题:统一文字点评与分数奖励的机制,并应用于智能体训练中。
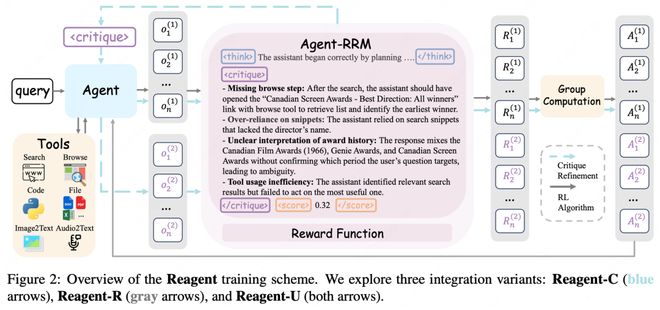
研究人员提出了三种应用方法,可视为不同程度的增强:
① 添加评论而不修改模型(Reagent-C)
最为轻量的一种方式是不改变代理参数,在推理过程中增加一个“听取评价”的步骤。
具体流程为:智能体先完成任务,然后由Agent-RRM提供一段批评意见,指明关键问题点,并让其根据这些反馈重新执行。这相当于给现有的大模型添加了一个“老师指导后再提交作业”的环节。
② 在奖励中加入过程分数(Reagent-R)
进一步改进的方法是将Agent-RRM生成的评分作为额外奖励因素纳入考量。
原先训练时仅依据任务是否完成来决定奖励,现在则是综合考虑“结果正确与否”和“思考及工具使用的质量”。这在处理需要多个步骤或涉及多种工具的任务中尤为重要,有助于减少由于单一错误导致全盘失败的情况。
③ 综合首次尝试与批评后改进的训练(Reagent-U)
这是文章重点介绍的方法——Reagent-U。它将上述两种反馈机制结合起来使用:
- 其中,一方面教导智能体在初次执行时尽量避免低级错误;
- 另一方面也教会其根据收到的批评意见进行调整。
在训练过程中,同一个问题会有“首次尝试”和“听取评论后的第二次尝试”两条路径。两者都接收“结果奖励+过程分数”,并共同参与优化循环。这种方法的好处在于:模型不会仅仅关注单一任务的成功率,而是全面学习如何清晰思考、有效使用工具以及根据反馈调整策略。
实际部署时,Reagent-U可以不依赖外部的Agent-RRM来提供点评,直接像普通的代理一样运行——那些“老师评语”已经被整合进模型参数中了。
这种设计带来了哪些改进?
在实验过程中,作者主要关注三个方面:文本批评的有效性、过程评分是否有助于强化学习以及统一后的实际效果如何。
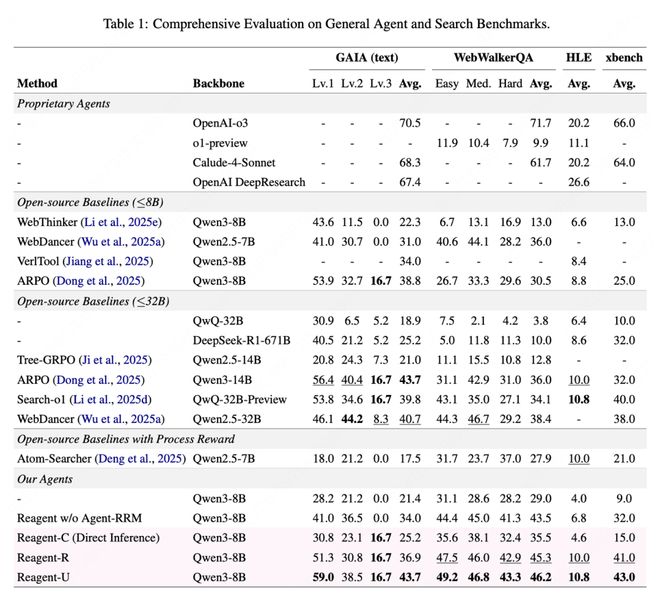
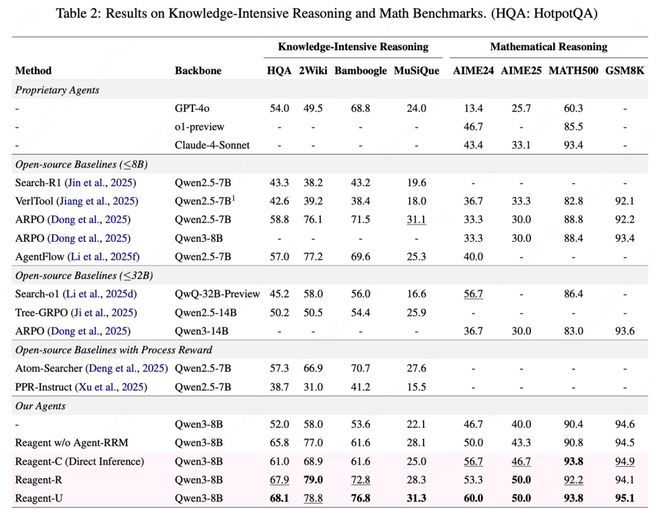
首先,在较轻量的方法上——仅增加一段评论而不修改参数的情况下,结果显示在许多数学和搜索任务中,“听取Agent-RRM的评价后再执行一次”确实能够显著提高正确率。
当过程评分被纳入训练后,智能体不再只是迎合最终的结果信号,而是更倾向于选择那些虽然目前未完全完成但整体思路正确的路径。
最终,在Reagent-U中将文本批评和奖励分数统一起来时,提升变得更为明显:
在GAIA这一通用代理基准的文本子集上,基于8B模型的Reagent-U取得了43.7%的成绩,接近甚至超越了一些更大规模的开源代理。在WebWalkerQA、HLE、xbench等复杂任务中也普遍优于仅依靠终局奖励版本的表现。
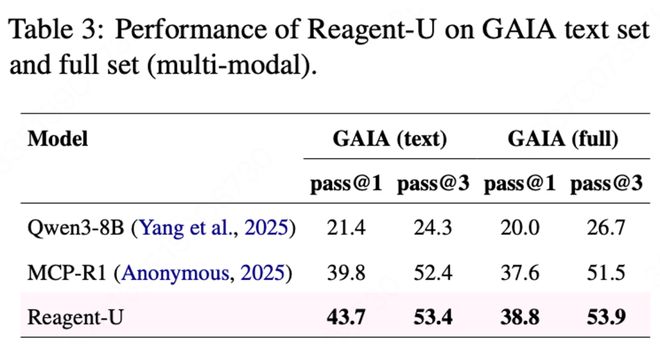
作者还测试了模型在整个GAIA集上的性能,在面对多模态通用代理任务时,Reagent-U依旧能够表现出色。
香港中文大学与美团合作推出的这套Reagent框架,将“对过程打分”的方法引入到了智能体训练中。实践证明,只要能评估思考过程,8B级别的代理在很多复杂任务上也能取得不俗的成绩。
更多细节请参考论文原文。