
视频生成扩散模型体积日益增大:从 2B 到 5B 再到 14B 等,效果显著提升的同时,训练和推理的成本也急剧上升。社区希望利用量化技术缩小模型规模,降低显存及计算成本,使其能在更多设备上运行并实现低成本部署。然而实际情况并不乐观:一旦使用 3/4 比特,视频生成的量化感知训练(QAT)相比图像更加难以处理且稳定性较差,画质下降幅度更大——不是轻微减少质量,而是变得无法接受。

图表展示了 CogVideoX-2B 模型在 4-bit 下逐通道权重和逐 token 激活量化的对比效果。(a)原始模型;(b)论文提出的方案;(c-e)现有的量化感知训练方法;(f)现有的后训练量化策略。
香港科技大学、北京航空航天大学及商汤等机构提出了一种专门针对视频生成扩散模型的 QAT 方法——QVGen,该技术在 3-bit 和 4-bit 下都能够显著提高质量,并首次让 4-bit 接近全精度的表现成为可能。目前,这项研究已被 ICLR 高分接收:评审前评分 88666(占 1.4%),评审后评分升至 88886(占 0.5%)。

- 论文详情请访问 https://arxiv.org/pdf/2505.11497
- 源代码可以在 https://github.com/ModelTC/QVGen 上找到。
- 可在 Hugging Face 平台上访问模型,网址为 https://huggingface.co/collections/Harahan/qvgen
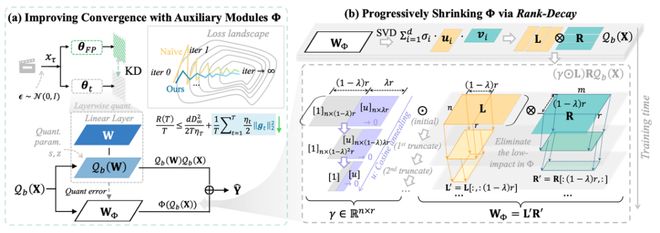
图表展示了 QVGen 的论文框架图。
为什么视频扩散模型的量化过程容易失败?
QVGen 的研究切入点非常明确:视频生成的 QAT 并不是简单地复制图像扩散模型的做法。作者在文中指出,相近规模和相似训练设置下,视频扩散模型的梯度范数明显更大,这会导致优化过程中不稳定性和难以收敛的问题,在低比特训练中尤为突出。
因此,如果不解决这些根本性问题,仅依赖常规量化技术进行修复是不够的,真正的落地应用会受到限制。
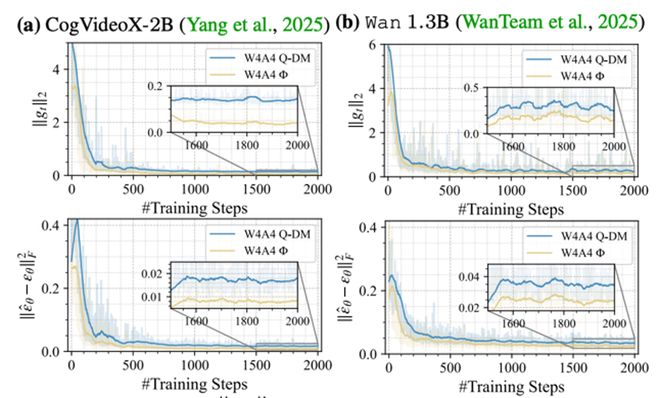
图表展示了已有方案(蓝色)与论文提出的方案(黄色)在量化感知训练中的梯度范数和损失对比情况。图表分别展示了 CogVideoX-2B 和 Wan 1.3B 模型上的可视化结果。
QVGen 如何做到:先解决训练稳定性,再减轻推理成本
QVGen 的核心思想是“在训练阶段增加稳定性,在推理阶段减少负担”,通过两步策略来实现看似矛盾的目标(见图表)。
第一步是在训练过程中加入辅助模块 Φ。这个模块的目的是为了在低比特条件下降低梯度范数,提高训练稳定性,使 3/4-bit 的 QAT 训练变得可行且效果良好。除了图表中的实验结果外,论文还提供了详细的理论支持。
第二步是在训练过程中逐渐移除 Φ 模块,让最终的推理阶段不再依赖该模块。作者观察到随着训练进行,Φ 参数中会积累越来越多影响较小的部分。因此,论文设计了 rank-decay 机制:通过分解和基于秩的正则化逐步减少这些低贡献部分的影响,直至完全移除 Φ。这一过程确保推理阶段几乎不增加额外成本,同时在训练期间提供稳定性红利。
实验结果表明:4-bit 接近全精度水平,3-bit 能够恢复质量
在主要实验中,QVGen 在 W4A4/W3A3 的设置下与其他量化方法进行了对比。结果显示,许多方法在 4-bit 下仍然存在明显退化现象,在 3-bit 更加严重;而 QVGen 却能在 3-bit 大幅恢复质量,并且在 4-bit 接近全精度(见图表)。
尤为重要的是,QVGen 并非仅适用于小模型。论文还展示了其在更大规模视频生成模型上的效果(如 5B、14B 等),即使在这些模型上依然能够保持接近全精度的表现(见图表)。
此外,该研究通过大量定性样例证明了 QVGen 不仅指标优异,实际应用中同样表现出色(见图表)。
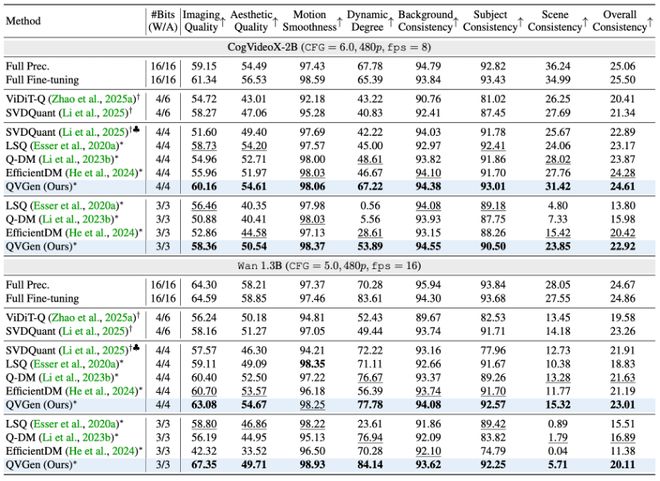
图表对比了 Wan 1.3B 和 CogVideoX-2B 模型在 VBench 上的性能表现以及 QVGen 的效果。
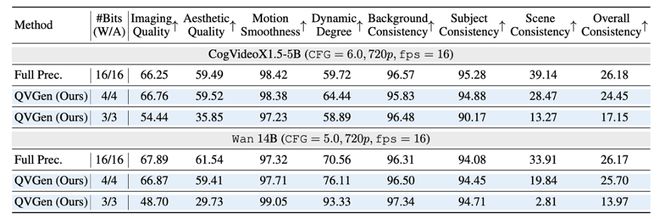
图表展示了 QVGen 在 Wan 14B 和 CogVideoX-5B 模型上的 VBench 结果。
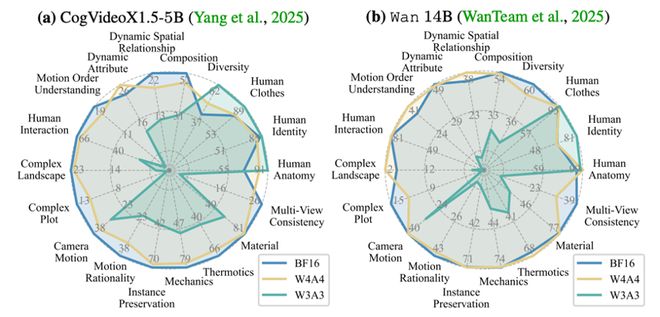
图表记录了 QVGen 在 Wan 14B 和 CogVideoX-5B 模型上的 VBench-2.0 结果。

图表比较了 QVGen 与现有方法在 Wan 1.3B 上的可视化结果对比。

图表展示了 QVGen 在 Wan 14B 上的实际效果。
不仅节省显存:带来真实加速,还能与其他加速手段结合使用
对于部署而言,低比特量化最直接的好处是显著减少内存占用。论文报告称可以实现高达四倍级别的压缩,并使模型能够在更小的设备上运行或提高 batch 大小和分辨率等配置。
实际应用中另一个关键点是:QVGen 使用标准均匀量化的思路,使其易于与现有的 W4A4 推理内核集成。论文进一步指出 QVGen 与其他视频生成加速方法可以正交叠加使用,如结合某些 3D 注意力机制的加速方案后,推理速度还能得到提升(见图表)。
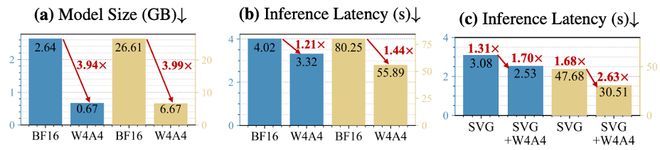
图表展示了模型大小、性能及与注意力加速技术结合后的加速效果对比情况。其中蓝色代表 Wan 1.3B 模型,黄色则为 Wan 14B 模型的表现。
训练成本是否会显著增加?论文的回答是否定的
很多读者担心:引入 Φ 辅助模块并进行 rank-decay 过程会大幅提高训练成本。然而,论文通过详细分析发现 QVGen 的额外训练开销几乎可以忽略不计(例如 GPU-days 和峰值显存变化很小),但其最终生成质量仍能显著优于现有方法(见图表)。
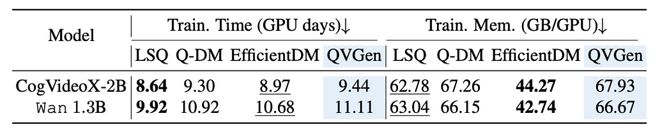
图表展示了 QVGen 与其它方法在训练时间和训练内存占用上的对比情况。
综上所述:视频扩散模型可以实现 4-bit 接近全精度,先稳住训练再减轻推理成本!
当前情况下,随着视频生成扩散模型规模的不断增大,当采用 3/4 比特量化时,常见问题是 QAT 训练不稳定、难以收敛以及画质显著下降。QVGen 的核心判断非常明确:解决低比特量化的关键在于稳定训练过程而非单纯的技术细节优化。
在这一问题上,QVGen 提供了一整套解决方案,具体包括:
- 引入辅助模块 Φ 以降低梯度范数并提高稳定性,使 3/4-bit 训练成为可能;
- rank-decay 过程逐步移除 Φ 模块,确保推理阶段几乎不增加额外负担;
- 支持 W4A4/W3A3 的低比特设置,并强调可与现有实现无缝对接;显著减少显存占用的同时还能与其他加速方法叠加使用。
总体而言,QVGen 在 CogVideoX 和 Wan 等视频扩散模型上实现了 4-bit 接近全精度及 3-bit 恢复至可用区间的成果,并且训练成本几乎无额外增加。对于希望将视频生成模型从“昂贵难用”转变为“更经济高效”的场景,QVGen 提供了一条切实可行的路径。