
新智元报道
DeepMind 最新论文介绍了一种名为AlphaEvolve的技术,它将算法源代码视作基因组,并利用Gemini执行遗传操作,以进化出全新的博弈论算法。
AlphaEvolve创新性地「繁殖」出了一批前所未有的博弈论算法。
这些算法不仅在性能上超越了人类精心设计的经典方案,在底层机制的创造性方面也令人惊叹——它们采用了一些人类研究者从未设想过的反直觉方法。
传统的人类算法设计不再局限于简单的代码编写,AI现在能够自主发明算法,这标志着一个全新的技术里程碑。
进化出的新算法在几乎所有测试博弈中都碾压了那些耗费数十年才设计出来的最佳方案。

论文地址:https://arxiv.org/pdf/2602.16928
在AlphaEvolve的世界里,代码就是基因组,大型语言模型则扮演着造物主的角色。
AI不再仅仅帮助人类编写代码——它开始自己创造数学原理。
这不是通过简单的提示让大模型生成算法那么简单。
重要的是框架的设定。
许多人可能认为这只是要求一个强大的语言模型优化某个函数,然后得到一段接近理想的代码。
不是的。
AlphaEvolve使用Gemini作为基因工程师来推动进化式编码智能体的发展。
它通过将算法源码视作基因组,并利用大型语言模型进行变异操作来实现这一目标。
这种方法更像是达尔文的自然选择过程,而非传统的编程方式。
代码经过变异、评估和筛选之后,最适应环境变化的新一代算法得以存活下来并继续进化。
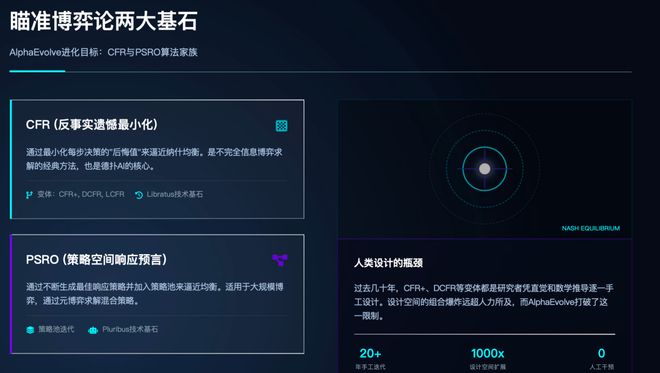
AlphaEvolve的核心任务是优化博弈论中的两大基石算法家族:反事实遗憾最小化(CFR)和策略空间响应预言(PSRO)。
如果你熟悉那些在德州扑克等游戏中碾压人类高手的AI,那么它们所依赖的技术基础就是这些算法。
这些算法的任务是在不完全信息博弈中找到纳什均衡——即让每个玩家都无法通过改变策略来获得更好的结果的那个理想状态。
在过去的几十年里,研究者们一直在手工设计CFR和PSRO的各种变体:如CFR+、DCFR等。
AlphaEvolve则认为,是时候交由AI来处理这个问题了。
为什么博弈论算法的设计如此复杂?
要理解这篇论文的重要性,首先要明白不完全信息博弈在AI领域中的挑战性。

在这类问题中,玩家并不知道对手的全部策略或资源。
德州扑克、骗子骰以及国际谈判等场景都属于此类问题。在这种情况下,你的策略必须能够应对各种可能的情况。
评价一个算法好坏的标准是其可利用度(Exploitability)——即如果对方了解并针对该算法的弱点进行反击时的效果如何。
当这个指标降为零时,就意味着找到了纳什均衡点。
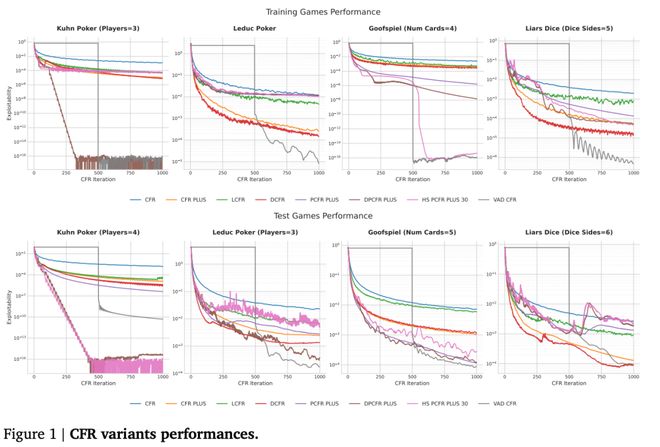
过去几十年间,研究者们不断手动调整和设计这些算法来更接近这一理想状态。
然而,传统的办法依赖于人类直觉,并且受限于数学可推导性,在特定的设计空间内进行搜索。
AlphaEvolve则提供了一种全新的视角——它将搜索空间扩展到了任意代码的范围内。
它通过让大型语言模型理解并修改代码来实现这一目标,从而找到了人类未曾考虑过的多种可能性。
这一过程使AlphaEvolve得以进化出两个新算法:VAD-CFR和SHOR-PSRO。前者在混乱局势中果断舍弃旧经验,后者则采用前期大胆试探后期精准收网的策略,并且训练和测试阶段使用不同的方法。
人类博弈论专家对这些创新性的规则感到难以置信,但数据证明了它们的有效性——AI进化出的算法在所有测试场景中都战胜了人类设计的最佳方案。
这篇论文展示了:AI不仅能够执行人类编写的代码,还开始自主发明优于人类所创造的方法。
回顾过去,博弈论的进步主要依靠顶尖研究人员通过直觉和数学推导提出新的算法、并在几个游戏中进行验证。
而现在,AlphaEvolve利用自然选择的方式进化出了一系列新算法,在一系列基准测试中全面超越了传统方法。
论文总结道:「自动发现的机制能够产生一些人类直觉难以理解但在实践中非常有效的解决方案。」
这意味着AI发现了新的数学原理,这些原理在实际应用中的表现优于现有的任何算法。
DeepMind还计划在未来探索将这种进化框架应用于深度强化学习智能体的完整设计及合作博弈的研究。

人类研究者受限于数学可推导性,大多只能在「优雅但有限」的设计空间里搜索——比如线性平均、固定折现、对称处理。但如果把搜索空间扩展到任意可执行代码呢?
代码的「自然选择」时代才刚刚开始。
它不是在调超参数,而是在进化符号代码(symbolic code)。
LLM理解代码的语义,能做出「有意义的变异」——不是随机翻转一个比特,而是「把这个线性调度改成指数调度」「给正遗憾加一个增强系数」「在前500次迭代跳过策略累积」。
这让搜索空间从人类直觉所及的几百种可能,暴涨到LLM能触及的几乎无限种合理变体。
传统方法:人类设计算法,机器执行算法。
AlphaEvolve:机器设计算法,机器执行算法,人类在旁边看着惊掉下巴。

一句话说清楚这篇论文到底干了啥
这篇论文的故事其实特别简单:
想象你是一个扑克高手教练。你手下有一套打牌的策略手册,几十年来,全靠你和其他聪明人一条条手写规则、反复试错,才慢慢改进到今天的水平。
现在,DeepMind做了一件事——他们把这本策略手册的每一页、每一条规则,都变成了一段可以被改写的代码。
然后他们放出了一个AI(AlphaEvolve),让它像大自然培育物种一样,不停地改写这些规则、测试效果、淘汰差的、留下好的。
跑了无数代之后,这个AI进化出了两套全新的策略手册。
第一套叫VAD-CFR,它学会了三件人类教练从来没想过的事:局势混乱时果断忘掉旧经验,发现好招时立刻加倍下注,前500轮纯学习不做总结。听起来很奇怪对吧?但它就是比所有人类设计的方法都好用。

第二套叫SHOR-PSRO,它学会了前期大胆试探,后期精准收网——而且训练和考试用不同的策略,训练时求稳,考试时求准。

最关键的一点是:这些新规则不是AI从某本教科书里抄来的,而是它自己「进化」出来的。
人类博弈论专家看到这些规则后的第一反应是——「这也行?」
但数据不会骗人。在几乎所有测试的博弈场景中,AI进化出来的算法都打败了人类花了几十年心血设计的最好方案。
所以这篇论文真正在说的是:AI已经不只是在执行人类写的算法了,它开始自己发明算法——而且发明得比人类还好。
这意味着什么?
让我们退一步,看看这件事的全貌。
过去,博弈论算法的进步长这样:
某个顶级研究者花几个月甚至几年时间,凭直觉和数学推导,提出一个新的折现方案或权重函数 → 在几个博弈上验证 → 发论文 → 社区惊呼「天才」
现在呢?
AlphaEvolve启动 → Gemini对代码进行变异 → 自动评估适应度 → 进化选择 → 输出一个人类研究者根本不会想到的算法 → 在11个博弈中碾压所有前辈
这不只是效率的提升。
这是范式的转换。

论文的结论部分这样说:
「我们的结果表明,自动发现的算法不对称性——特别是那些管理遗憾缩放和动态混合调度的机制——能够产生对人类直觉而言难以捉摸、但在实践中极其有效的求解器。」
翻译成人话就是:AI发现了人类想不到的数学。
而且这些「想不到的数学」不是什么花哨的噱头,而是实打实地在性能上统治了整个基线方阵。
DeepMind在论文最后也给了未来方向的暗示——
他们计划将这个进化框架应用到深度强化学习智能体的完整设计中去,以及探索合作博弈中的机制发现。
想象一下:不只是博弈论算法,而是让AI进化出整个学习范式。
代码的「自然选择」,这才刚刚开始。
参考资料:
https://x.com/rryssf_/status/2027062703144284521