谷歌前TPU员工创办的创业公司MatX正受到广泛关注,据传该公司比英伟达芯片更优秀。
正是因为卡帕西(他同时也是MatX最新B轮融资的投资方之一)的推荐,这家公司才被更多人所知晓。
卡帕西表示,参考英伟达4.6万亿美元市值,MatX正致力于解决当今最具挑战性和回报率最高的技术难题。
MatX团队非常出色,我很荣幸能参与其中,并向他们祝贺获得的新一轮融资!
除了卡帕西的支持外,MatX还拥有自己的独特技术路线——一条与主流AI芯片设计不同的方案。
近年来,在AI芯片领域中形成了两大阵营:
其一以英伟达和谷歌为代表,侧重于高带宽内存HBM的应用,优先解决大规模训练及吞吐量问题;
而另一派则由Cerebras Systems领衔,强调片上SRAM(静态随机存储器)与低延迟特性,在推理场景中占据优势。
但MatX选择了“鱼和熊掌兼得”的策略。
在他们看来,真正的关键不在于单一技能的极致表现,而是在同一芯片内同时实现“训练级吞吐”与“推理级低延迟”,尤其是在处理长上下文、Agent循环等复杂工作流程时更为重要。
这并非只是理论上的讨论,据MatX创始人透露,他们正致力于开发一款名为MatX One的专为大语言模型设计的新芯片:
该款芯片在吞吐量和延迟性能上均超越了现有市场上所有已知产品。

对于MatX来说,它究竟是谁?是否真的能够对英伟达构成威胁呢?
我们拭目以待,继续观察其发展动态。
谁是MatX?
人们对于这家公司的第一印象往往离不开与谷歌的关联。
这是因为两位创始人均曾是谷歌TPU团队的一员。
创始人兼首席执行官Reiner Pope,在软件领域具有深厚的背景。

自2012年加入谷歌后,他主要负责谷歌地图部分网页开发,并逐渐晋升为五人小组的小主管。
随后参与设计并实施了大型机器学习系统Sibyl的开发工作,该系统曾对YouTube、Gmail和Android等服务提供了重要支持,直至被更灵活且支持深度学习的TensorFlow Extended(TFX)平台所取代。
在2017年,他开始涉足芯片设计领域——加入谷歌内部项目孵化平台“登月工厂”(Moonshot Factory),专注于下一代计算架构的设计工作。
从那时起,他的角色逐渐由“系统开发者”转变为“模型与硬件协同工作的理解者”。
自2019年起,他担任了谷歌机器学习芯片技术主管兼架构师,并参与设计了两代ML芯片项目,在第二代中发挥了重要作用。
他还曾负责过谷歌当时最大的模型——PaLM的训练工作,且是该模型软硬件效率的关键负责人之一。
Reiner Pope可以被认为是早期谷歌TPU软件栈的重要成员之一,并深刻理解如何使大模型有效运行在芯片上。
创始人兼首席技术官Mike Gunter,则拥有明显的“硬件”标签背景。
在加入谷歌之前,他就已是一位连续创业者——早在2000年便与其他合伙人联合创办了一家无线通信芯片公司Gossett and Gunter,后来该公司被谷歌收购并随之进入谷歌工作。

他曾在谷歌从事无线通讯、多天线系统设计及ASIC开发等工作,并成为了谷歌首位逻辑设计师以及第一位获得“正式付薪写 Haskell”资格的工程师。
从2008年开始,他就负责了谷歌首个硬件加速项目的主导工作,该项目最终大幅提升了公司的计算效率。
此外,他还参与了台积电的合作计划,并计划于今年完成芯片设计,在2027年实现量产。
MatX表示,此次融资将有助于他们储备产能和零部件资源,确保一旦产品准备就绪就能迅速投入市场。
这轮融资让我们几乎站在与那些资金雄厚的大公司相同的起跑线上。
除此之外的另一件事:
当我们想到前不久被老黄以200亿美元收购的Groq时,不禁对MatX未来的发展充满了期待和好奇。
因为这两家公司都经历了相似的故事——同是谷歌TPU核心成员创办、同样致力于挑战英伟达芯片霸主地位。
而对于MatX而言,其创始人兼CTO Mike Gunter还曾有过被谷歌打包收购的经历……

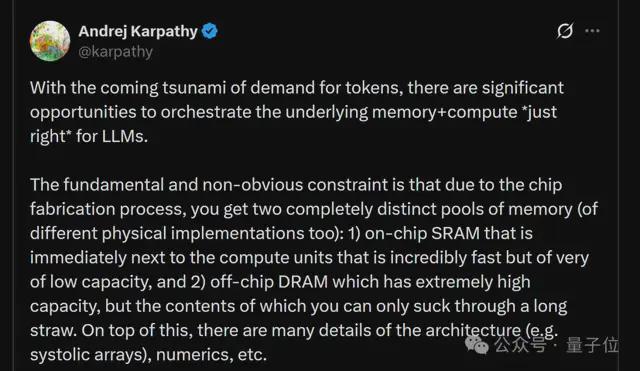
为便于理解,我们可以结合卡帕西的观点来解释。
在卡帕西看来,随着token用量的激增,如今大家面临的问题是——
怎么把“算力”和“内存”调配到刚刚好,才能让大模型更快、更便宜地吐出更多token?
很多人没有意识到,目前市面上两种主流的芯片路线都有其局限性:
以英伟达为代表的HBM路线,其核心逻辑在于“大模型训练是带宽游戏”,即模型越大、参数越多、上下文越长,就越需要把权重和激活值在芯片之间高速搬运。
于是堆HBM、堆带宽、堆互连,成为主流解法,它解决的是吞吐问题。
而以Cerebras Systems为代表的片上SRAM路线,其核心逻辑在于“推理时代的关键不是带宽,而是响应速度”。
于是把尽可能多的数据放在片上SRAM中成为解法,如此一来便能减少外部访存,降低单次查询延迟,后者解决的是延迟问题。
但问题在于,今天的大模型,其训练和推理不再是泾渭分明的两个世界——
如果只强调HBM带宽,延迟难以下降;如果只强调片上SRAM,规模又难以扩展。
所以卡帕西就问了,是否存在一种更优的物理基板,使计算与内存的比例从一开始就为大模型而设计?
MatX的回答是:与其在既有架构上打补丁,不如从架构层面重构算力与存储的关系。
没错,就是从零开始。
2022年从谷歌离职创办MatX,二人便下定决心要从零打造一款更优秀的芯片——
目标是设计一条全新的、具有竞争力的硬件产品线,融合其他芯片制造商使用的两种截然不同的方法。
MatX试图证明,未来的AI芯片不必在“速度”和“容量”之间痛苦权衡,因为真正的软硬结合,可以让芯片同时拥有两者的优势。按Reiner Pope的话来说就是:
- 实际上可以在同一个产品中同时做到这两点,而且这样会得到一个更好的产品。
而正在孕育的MatX One,毫无疑问便承载着这一理念。
一旦成功,同时实现更高的吞吐量+更低的延迟便意味着——
在同样的预算下,你可以训练更大的模型、跑更长的上下文、支撑更复杂的Agent循环,同时让每一次用户交互都更快地得到响应。
这正是卡帕西所说的“设计最优物理基板,编排内存与计算,以求最快、最便宜地获取token”的现实注脚。
显而易见,从团队到理念到产品,MatX已经做足了准备。
而对这样一支团队,市场也给予了足够的注目和支持。
明年量产、已获数十亿融资
截至目前,这家公司已经获得数十亿美元融资。
MatX官网显示,2025年3月这家公司获得了1亿美元A轮融资,领投方为Anthropic早期投资者Spark Capital。
顶级量化Jane Street Group、知名投资人Daniel Gross(早期投资了Figma/Notion等)、Nat Friedman(GitHub前CEO)、Adam D‘Angelo(Quora联创兼CEO)等均参与投资。
当时Reiner Pope还对MatX做了一个阶段性总结:
- 两年内,我们在机器学习数值计算、芯片设计和实现、软件和系统设计等方面的所有技术投入都得到了验证,并建立了所有必要的合作伙伴关系,从而开发出了我们的芯片。
- 凭借这一轮投资,我们现在拥有足够的资金将我们的系统推向市场。

而在快速发展近一年后,规模接近100人的MatX这次又获得了最新5亿美元(约合人民币34亿元)B轮融资,而且阵容还在增加。
具体而言,B轮领投方变成了两家:Jane Street和Situational Awareness LP。
原有投资方Spark Capital、Triatomic Capital、Harpoon Ventures等继续跟投,而且还新增了Dwarkesh Patel、卡帕西、 Stripe联创兼CEO Patrick Collison及其弟弟等人。
Reiner Pope继续总结陈词:
- 创立MatX的初衷是,我们认为最适合LLM的芯片应该从根本上进行设计,并深刻理解LLM的需求及其发展趋势。为了打造这样一款芯片,我们甚至愿意放弃小模型性能、低容量工作负载,以及编程的便捷性。
可以说,此举已经将人们对MatX One的好奇心拉满了。
内部测试表明,根据每平方毫米的计算性能指标,其芯片性能可以超越英伟达即将推出的Rubin Ultra产品。
据悉MatX将与台积电展开合作,目标是今年完成芯片的全部设计,并于2027年开始出货,主要销售对象为少数几家领先的人工智能实验室。
MatX表示,这笔融资将帮助公司预留产能和零部件,以确保一旦准备就绪就能迅速发货。
- 这一轮融资让我们几乎与那些拥有巨额资金的公司站在了同一起跑线上。
One More Thing
联想到刚被老黄打包收购的Groq,我们实在想看MatX的未来。
毕竟这两家手上拿的剧本可太一致了——
同是谷歌TPU核心成员创业、同是要挑战英伟达芯片霸主地位。
结果呢,老黄甩出200亿美元就把Groq打包带走了——包括创始人和90%团队员工。
更别说MatX创始人兼CTO Mike Gunter还有被谷歌打包收购的经历……
只能说,如果MatX真做出了比英伟达芯片更好的东西,不说老黄有没有想法,谷歌可能也去争一争也不一定。
