
语音情感识别(SER)过去一直遵循相同的模式:输入语音,输出情绪标签。这种做法在技术实现上是有效的,但在认知层面上却过于简化。
在人际交流中,对情绪的判断从来不是简单的“标签选择”,而是一个基于证据整合的过程。人们会结合语调变化、音高波动、语速快慢、重音位置以及语义内容,并考虑说话人的身份特征来推断对方的情绪状态,比如愤怒或失落的原因。
因此,一个核心问题被提出:
SpeechLLM 是否具备像人类一样能够解释其情绪判断依据的能力?
针对这一挑战,研究团队提出了EmotionThinker——首个专注于可解释情感推理的强化学习框架,旨在将 SER 从单纯的“分类任务”提升到基于多模态证据进行推理的任务。

- 论文标题:EmotionThinker: Prosody-Aware Reinforcement Learning for Explainable Speech Emotion Reasoning
一、从 “情绪分类” 到 “情感推理”
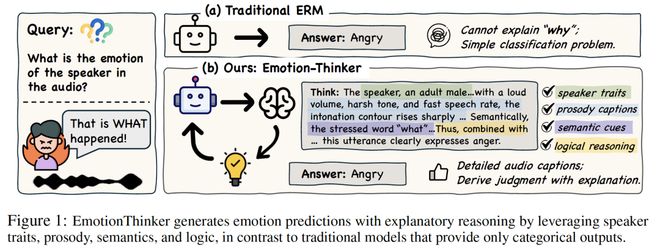
EmotionThinker 对语音情感识别任务进行了重新定义,将其扩展为情感推理任务。在新的设定中,模型不仅要预测情绪标签,还需要生成一段解释说明:
- 哪些声学线索支持这一判断
- 哪些语义线索起到关键作用
- 这些线索如何共同支撑最终结论
此种转变意味着,模型的输出从简单的标签升级为“标签+基于证据的推理”。
该变化的意义不仅在于延长了输出内容,更在于重新定义了优化目标。模型不仅要准确预测情绪,还要学会整合韵律、语义和说话人属性等多模态信号,并在解释中体现这些线索如何支持最终结论。
二、EmotionThinker:
面向可解释情感推理的框架
EmotionThinker 的目标不仅在于提升情绪识别的准确性,还旨在增强以下三个方面的能力:
(1)提高情绪识别的准确率
(2)增强对情绪线索的整合与推理能力
(3)提供更细腻的声音描述,涵盖说话人的特征、韵律信息和语义内容。
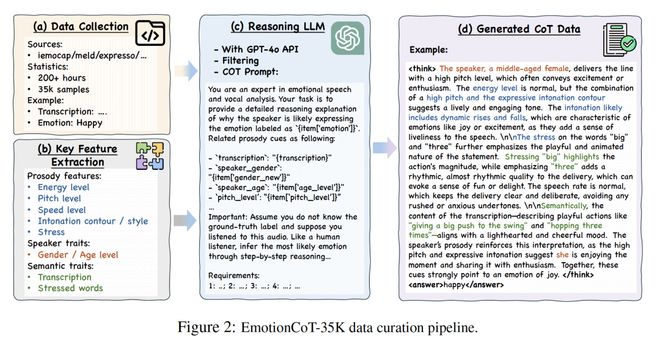
为实现这一目标,研究团队构建了EmotionCoT-35K 数据集。该数据集包含超过35,000个样本,每个样本不仅提供了情绪标签,还详细标注了音高、能量水平、语速等线索如何支持这些情绪判断。
这些样本的细粒度韵律描述和结构化推理解释使模型能够学习到 “证据 — 推理 — 结论” 之间的关联性。
同时,研究团队注意到,若模型在感知语音节奏方面能力不足,则其情感推理的能力也会受到限制。因此,他们进一步开发了 EmotionThinker-Base ,通过监督微调增强模型对音高变化、能量波动、语速模式和重音等结构的感知力。
三、GRPO-PTR:
提升强化学习中的解释能力
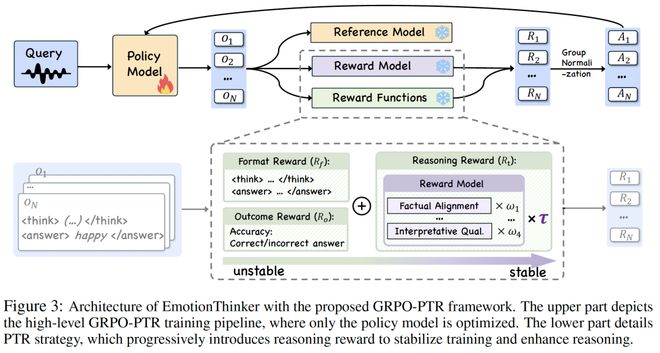
在将语音情感识别任务重新定义为情感推理之后,如何在开放生成场景中对“推理质量”进行稳定的强化学习成为新的挑战。直接叠加情绪预测奖励和推理奖励会导致显著的噪声问题;模型可能产生看似合理但与最终情绪判断不符的解释。为此,研究团队提出了GRPO-PTR(Progressive Trust-aware Reasoning)。
首先,采用了渐进式推理奖励调度策略,在训练初期重点优化情绪预测的稳定性,并逐步增加推理奖励权重,使模型从“正确预测”过渡到“合理解释”。这种安排减轻了早期高方差信号对整体训练稳定性的干扰。
其次,引入了一种基于一致性的可信度加权机制。当模型生成的推理与最终情绪判断保持一致时,其推理奖励按完整权重计算;若二者存在冲突,则推理奖励自动减少。这有效解决了开放生成任务中常见的reward misalignment问题,确保解释优化始终服务于准确的情绪判断。
从优化角度看,GRPO-PTR 解决了多目标生成任务中的一个更一般性的问题:如何在强化学习框架下实现结构化推理与最终决策的对齐,并稳定收敛。
四、实验结果与研究启示
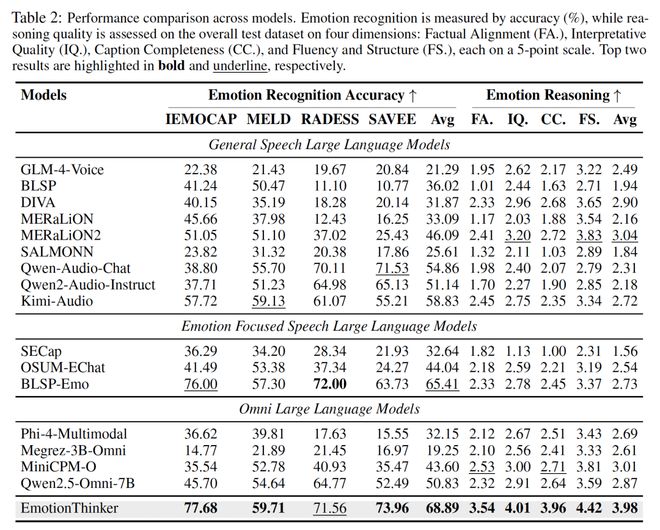
在多个标准语音情感识别基准上,EmotionThinker 表现出了:
- 更高的情绪识别准确率
- 更优的解释质量
- 更稳定的韵律线索整合能力。
关键发现是:当模型被训练以对齐声学线索和情绪判断时,在复杂情境下的鲁棒性显著提高。这表明,情感理解的瓶颈不仅在于语义层面,还在于声学与语义信号协同建模的能力。换句话说,如果模型不能准确理解“怎么说”,就无法稳定地识别出“是什么情绪”。

结语
EmotionThinker 不仅提升了情感识别任务中的准确性,更在任务定义上完成了一次转变:从简单的标签预测到基于多模态证据的结构化推理过程。
情绪识别不应只是标签分类,而是基于多模态证据进行合理解释的过程。这一转变标志着情感理解进入了一个强调可解释性和结构协同的新阶段。
当模型学会如何解释情绪时,它不仅在给出判断,还在展示其整合声学与语义线索的能力。
这或许是迈向真正情感理解能力的关键一步。
作者简介
本文第一作者为王丁冬,香港中文大学博士生,研究方向为语音大模型的口语理解,对话与推理 (Reasoning),导师为 Helen Meng 教授。本文在微软刘树杰博士与Jinyu Li博士的共同指导下完成。