
过去两年间,大型语言模型在推理领域的进步显著。
从数学与编程生成到解决复杂的逻辑和科学问题,这些模型不断刷新基准测试的记录。随着“推理模型”概念的兴起,越来越多的研究开始将推理能力视为通向通用人工智能的关键标志。
在能力迅速提升的同时,一个更为基础的问题逐渐显现:当模型在执行推理任务时出现错误,这些失误是随机波动还是表明了深层次的设计缺陷?
近期发表于 TMLR 的论文《大型语言模型推理失败》对该问题进行了系统性探讨。这项研究没有陷入“模型是否真正理解”的哲学争论中,而是采取了一种更为实际的方法——通过分析现有文献中的失败案例,构建一个统一的框架来全面审视大语言模型在推理方面的不足。

- 研究表明,在当前以性能为导向的研究环境中,这类工作尤为必要。
- 该论文作者宋沛洋是加州理工学院计算机专业的一名本科生,这项研究是他访问斯坦福大学人工智能实验室期间完成的;韩芃睿则是伊利诺伊大学香槟分校计算机系研究生,此项研究源于他的本科阶段。指导老师 Noa Goodman 是斯坦福大学计算机和心理学教授。
从“性能提升”到“失败结构”
在近年来的大规模模型研究中,重点几乎始终放在了性能的提升上。通过规模扩展、提示工程、思维链以及强化学习对齐等方法,持续推动着模型在标准基准测试中的表现。
相比之下,系统性地分析错误模式却长期处于分散状态。例如,在逻辑推理中的不一致问题、数学结构泛化的困难、社会情境下的不稳定行为和物理推理中的常识缺乏等现象,这些问题分布在不同的研究领域中,并没有一个统一的视角。
该论文的核心贡献在于将这些看似孤立的现象整合到一个系统性的框架里,从而揭示它们之间的潜在联系。
研究提出了一种二维分类体系。一条轴线描述“推理类型”,另一条轴线描绘“失败性质”。通过这一结构,不同领域的研究问题可以在同一个坐标系下被理解和比较。
三类推理:从语言逻辑到物理环境
在推理类型的维度上,论文区分了三种主要形式。
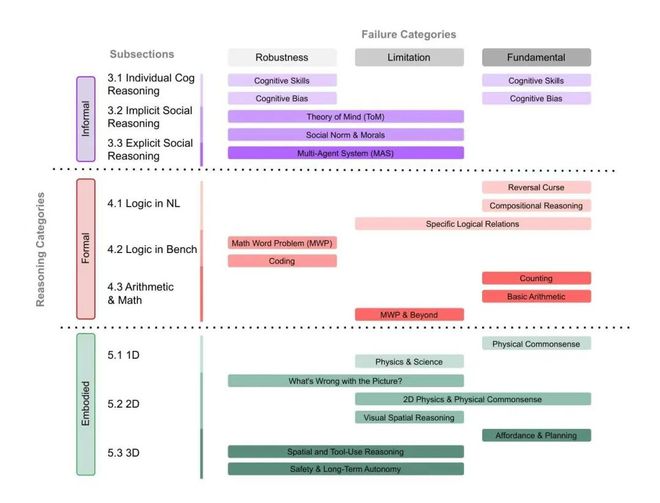
第一类是非具身的非正式推理,包括直觉判断、认知偏差和社会语境中的推断。这类能力在人类的认知发展中占据基础地位,但在大型语言模型中往往表现出高度不稳定性。
第二类是非具身的形式化推理,涵盖自然语言逻辑推断、组合推理以及数学和代码生成等任务。这是当前推理模型竞争最激烈的领域,也是结构性失败频繁出现的地方。
第三类是具身推理,涉及物理常识的理解、空间关系的认知、工具的使用及在真实或模拟环境中的行动规划。当模型从文本世界过渡到物理环境时,这类问题更为突出。
这一分类不仅仅是对任务类型的简单罗列,而是旨在揭示不同推理场景之间的认知结构差异。
三类失败:结构性、领域特定与鲁棒性
在失败性质的维度上,研究将现有文献中的问题归纳为三大类。
第一类是根本性的失败。这些问题通常源自模型架构或训练目标本身,在跨任务中具有普遍性。它们往往在不同推理场景下反复出现,并且难以通过简单的数据扩充来解决。
第二类是指定领域的限制。尽管模型在某些特定领域表现出明显的短板,但其他领域的进展却十分显著。这类问题通常与任务结构、领域知识或推理深度相关。
第三类是鲁棒性问题。即使语义保持不变,任务形式的轻微变化也会导致输出结果的大范围波动。这一现象在标准基准测试中尤为常见,并且也经常出现在社会推理和多智能体协作的情境下。
通过这一分类可以看出,不同领域中的失败现象并非彼此孤立。许多根本性问题会跨越不同的推理类型反复出现,而鲁棒性问题则揭示了模型内部推理结构的不稳定性。
结构共性:从训练目标到内部机制
论文进一步指出,多个失败现象可以追溯至相似的结构根源。
自回归训练目标使模型倾向于进行局部模式补全而非全局建模。这种倾向在形式化逻辑推理与长程规划任务中尤为明显。注意力分散效应也可能导致复杂的组合结构整合能力不足。
在具身推理场景下,由于缺乏真实世界的感知和反馈闭环,模型内部表示难以形成稳定的物理因果模型。这种缺失不会立即表现在纯文本基准测试中,但在动态环境中会被放大。
随着模型规模的扩大,部分能力确实得到了显著提升,但某些结构性问题并未同步消失。这一观察表明,仅依赖于规模扩展可能不足以解决所有推理缺陷。
成熟阶段的关键步骤
该论文发布后,在海外社交媒体上引发了广泛的讨论。
在 X(原 Twitter)平台上,有评论指出这是“近年来最令人不安的大型语言模型推理论文”。这种担忧并非由于提出了夸张结论,而是因为这篇论文系统地梳理了大语言模型在推理方面反复出现的问题模式,而没有展示新的 SOTA 模型或 leaderboard 成绩。
当社区沉浸在性能跃升的故事中时,这种对结构性缺陷的全面回顾具有冷静甚至反思的意义。
回顾计算机系统的发展历史可以发现,在性能提升的同时,对故障结构的分析始终是迈向成熟阶段的重要标志。早期计算机工程依赖于 fault tolerance 研究不断改进架构设计,而安全关键行业则通过事故复盘建立可靠机制。
在大语言模型向推理模型时代迈进的过程中,系统性地整理失败模式同样具有基础意义。
论文指出,未来的研究应该更加重视失败基准的长期更新与跨模型比较。与其专注于单一性能指标的提升,不如建立能够追踪顽固失败模式的评测体系,并观察哪些问题在不同代际中持续存在。
同时,推理评估也需要逐步从静态分数导向转向结构稳定性和行为一致性综合衡量的方式。只有当具体的推理崩溃现象可以追溯至内部机制层面,改进路径才会更加明确。
理解失败才能建立可靠的推理系统
大语言模型的推理能力仍在快速发展之中。然而一个成熟的推理系统不仅要在理想条件下取得高分,在复杂环境中也应保持结构稳定,并在面临故障时具有可预测性和可解释性。
《大型语言模型推理失败》所做的,正是为这一方向奠定基础框架。
在关注能力竞赛的同时,深入理解并分析错误或许将成为下一阶段人工智能研究的关键课题。
《Large Language Model Reasoning Failures》所做的,正是为这一方向提供基础框架。
在能力竞赛之外,系统理解失败,或许将成为下一阶段人工智能研究的关键课题。